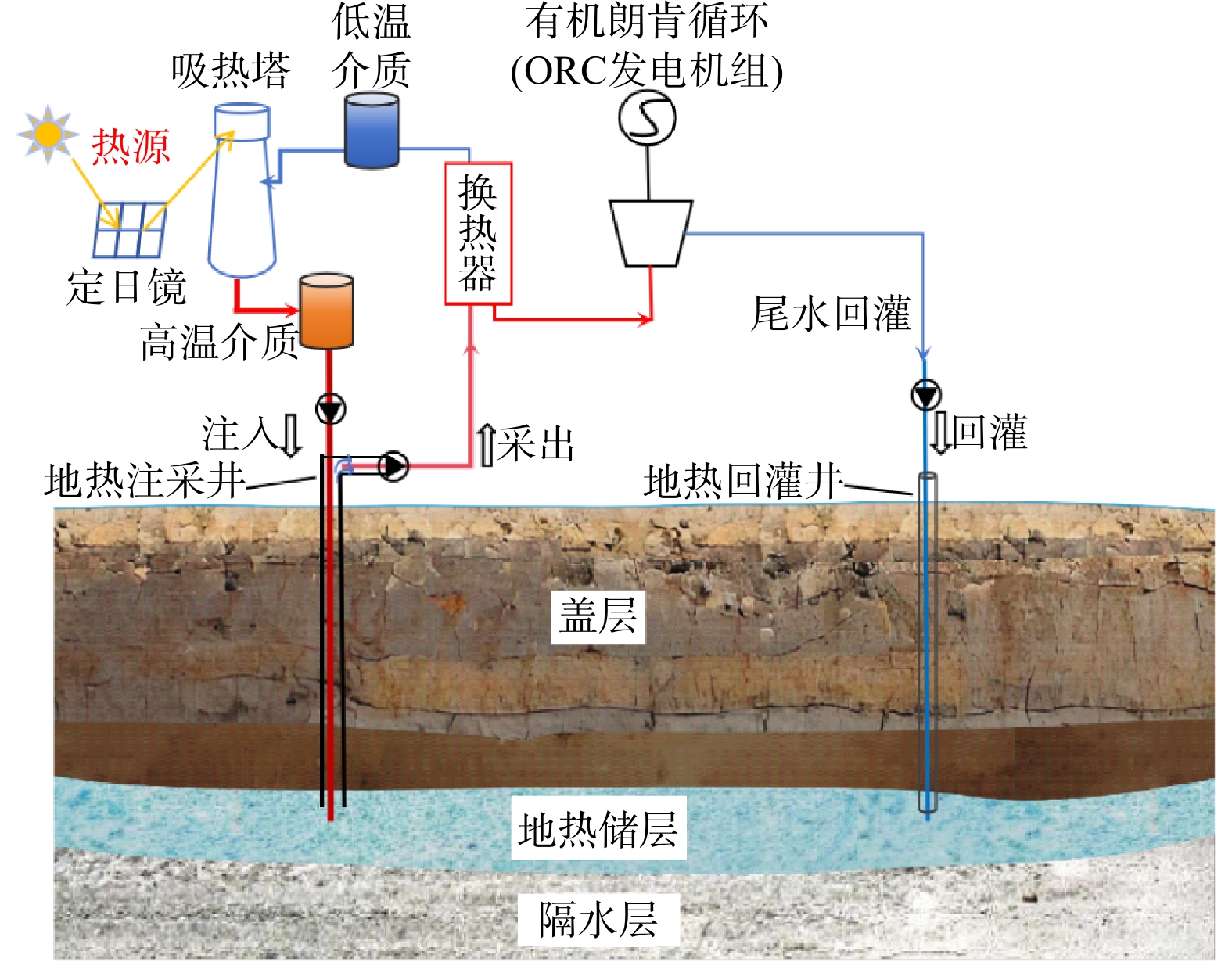
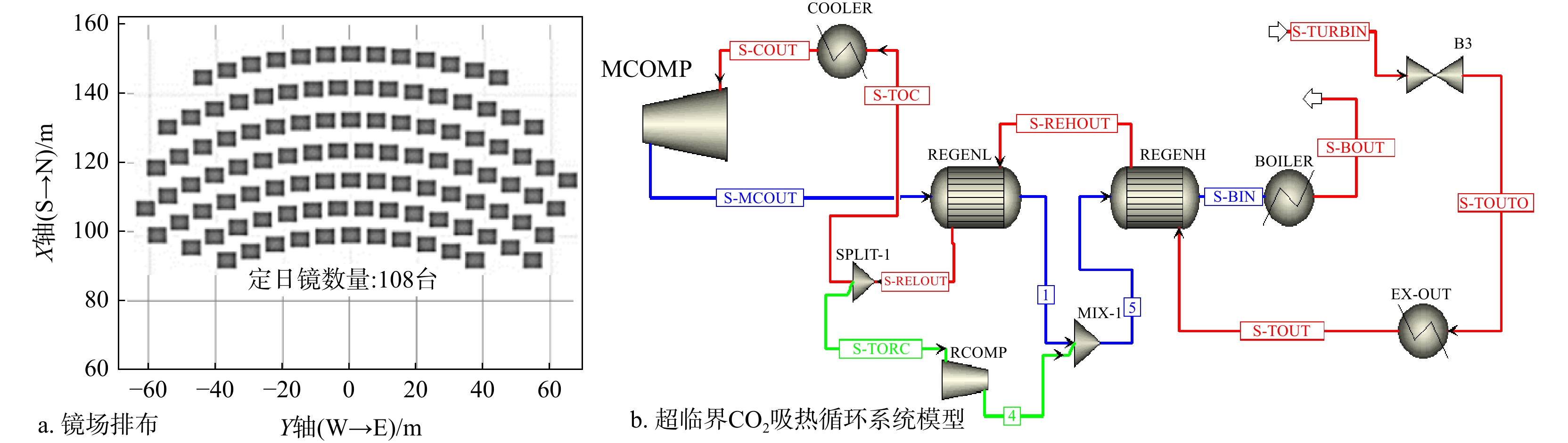
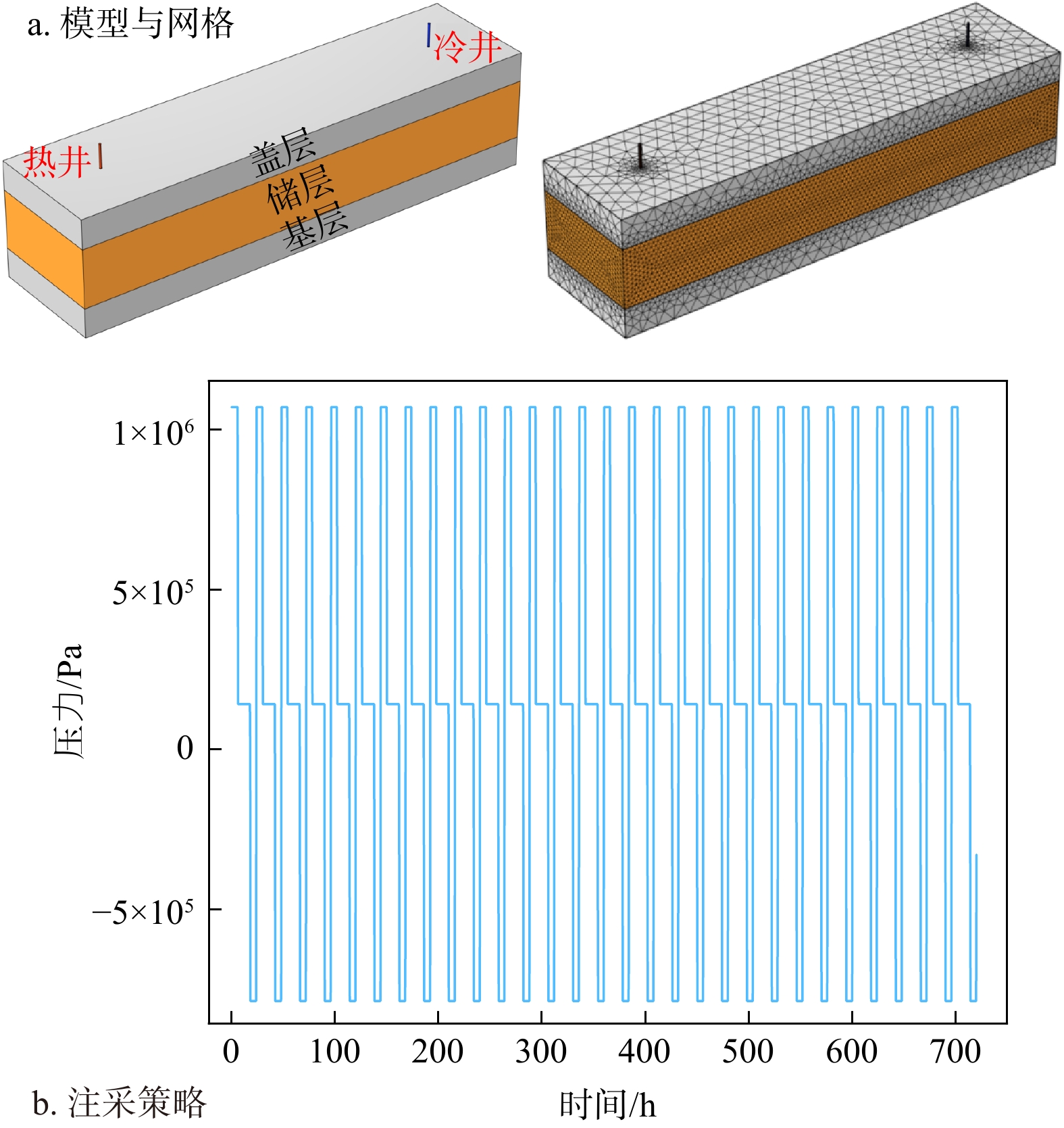
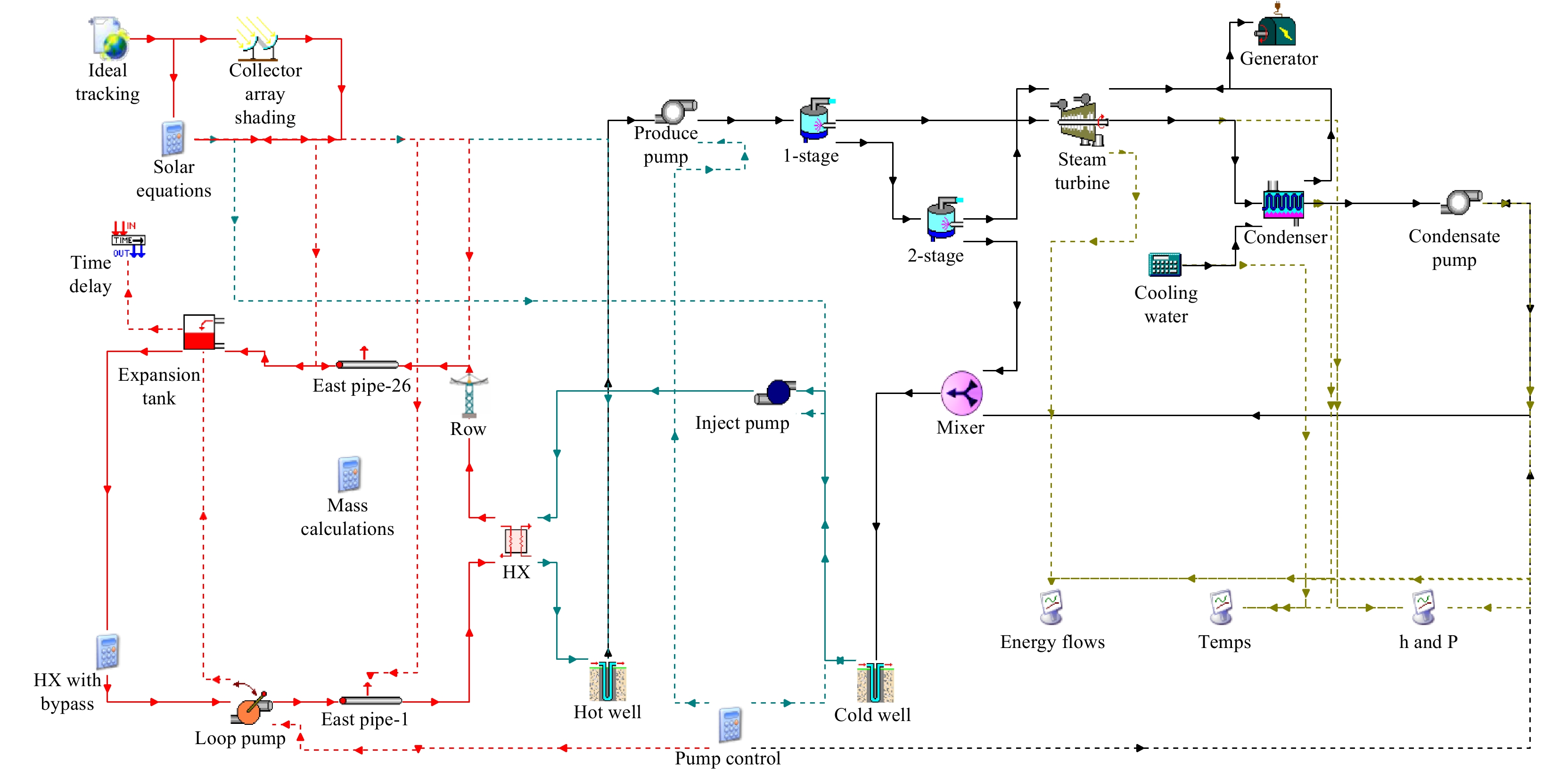
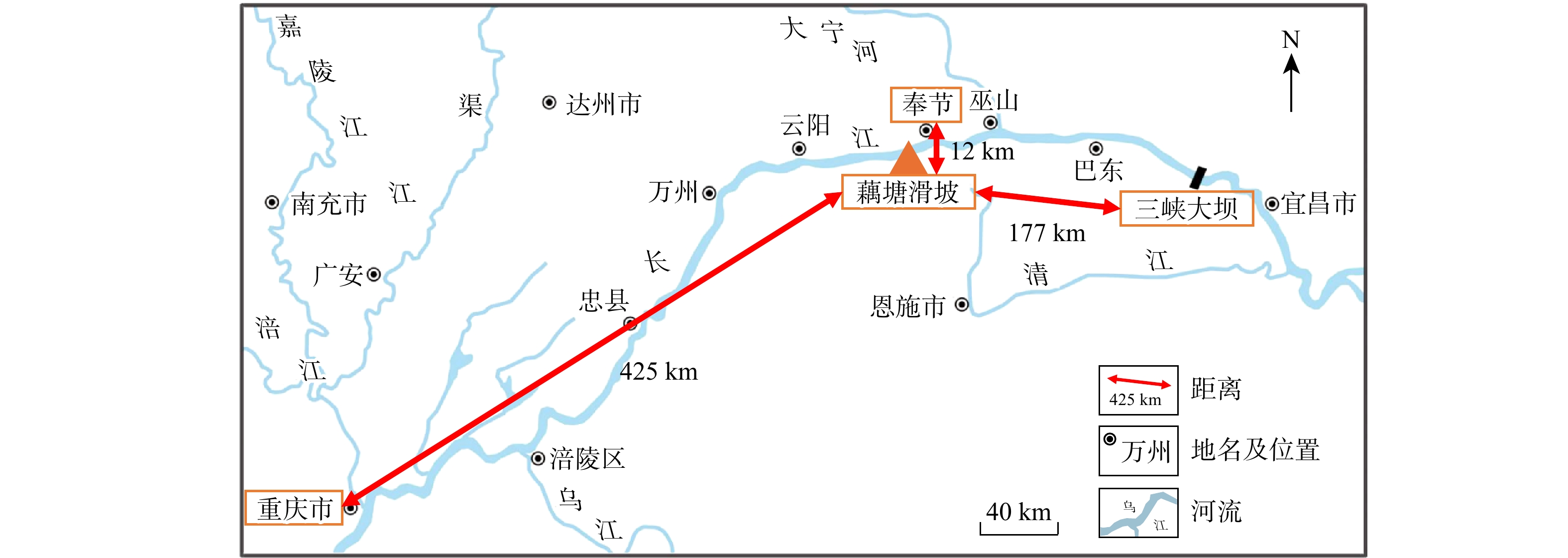
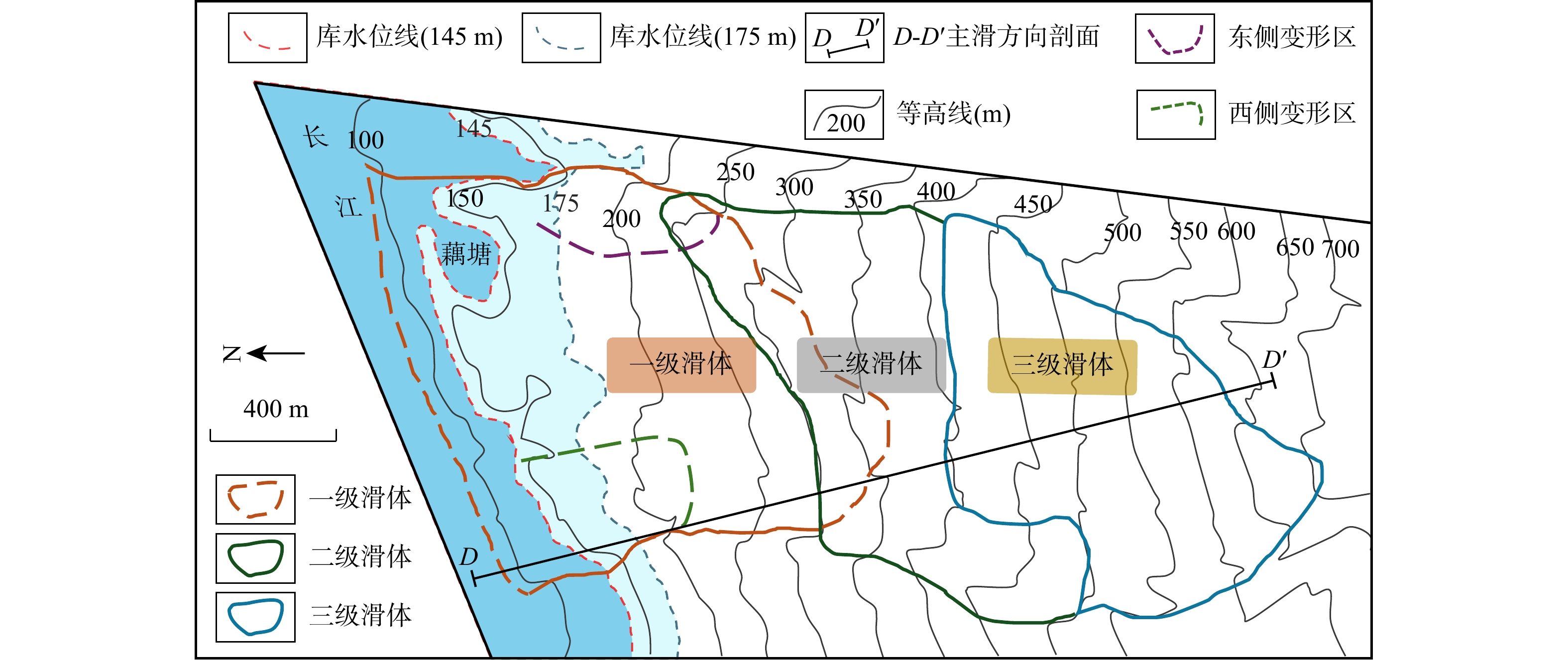
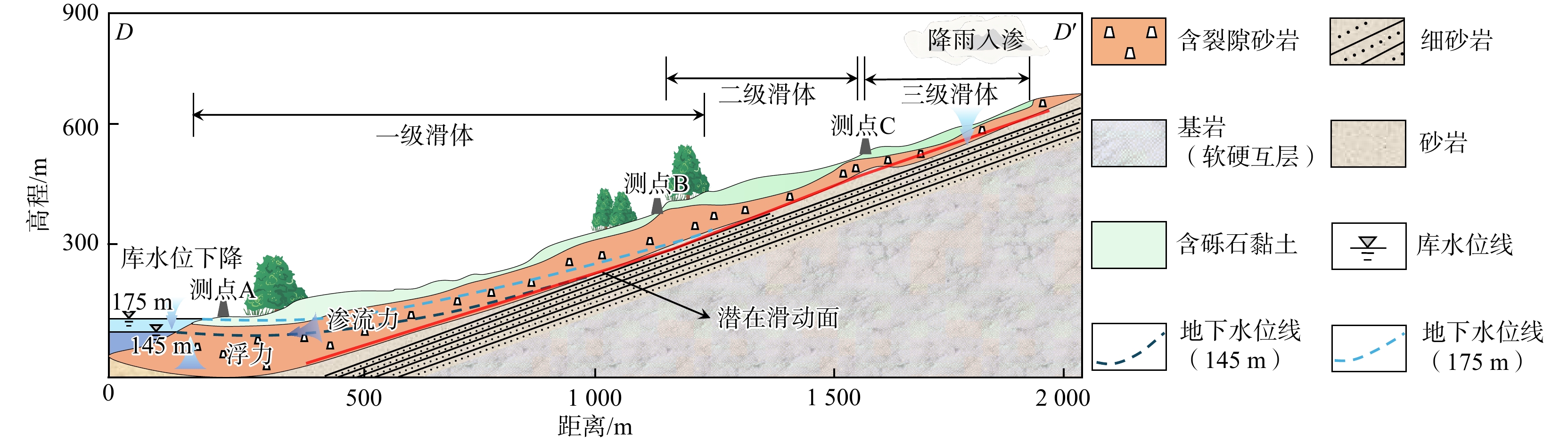
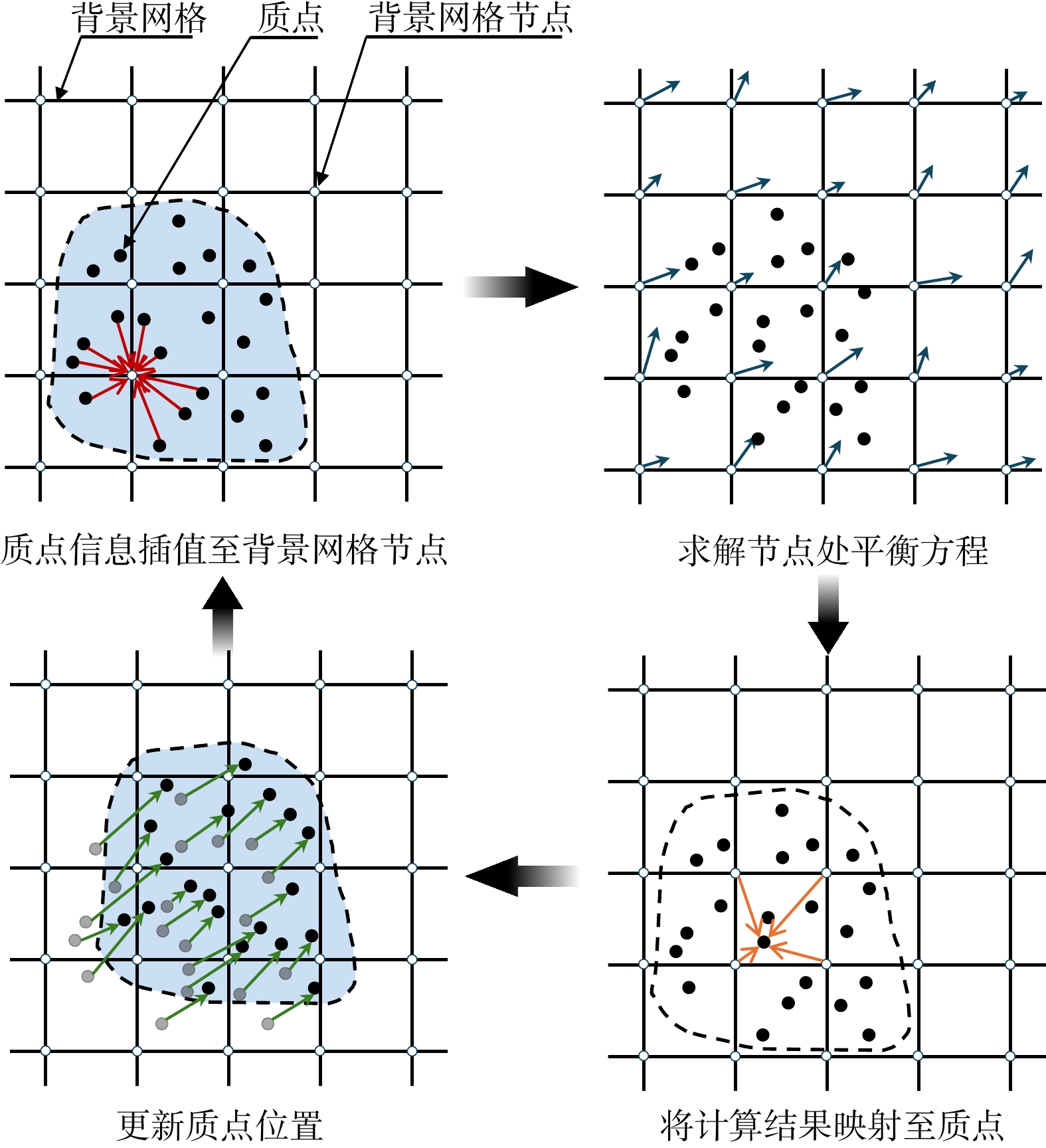
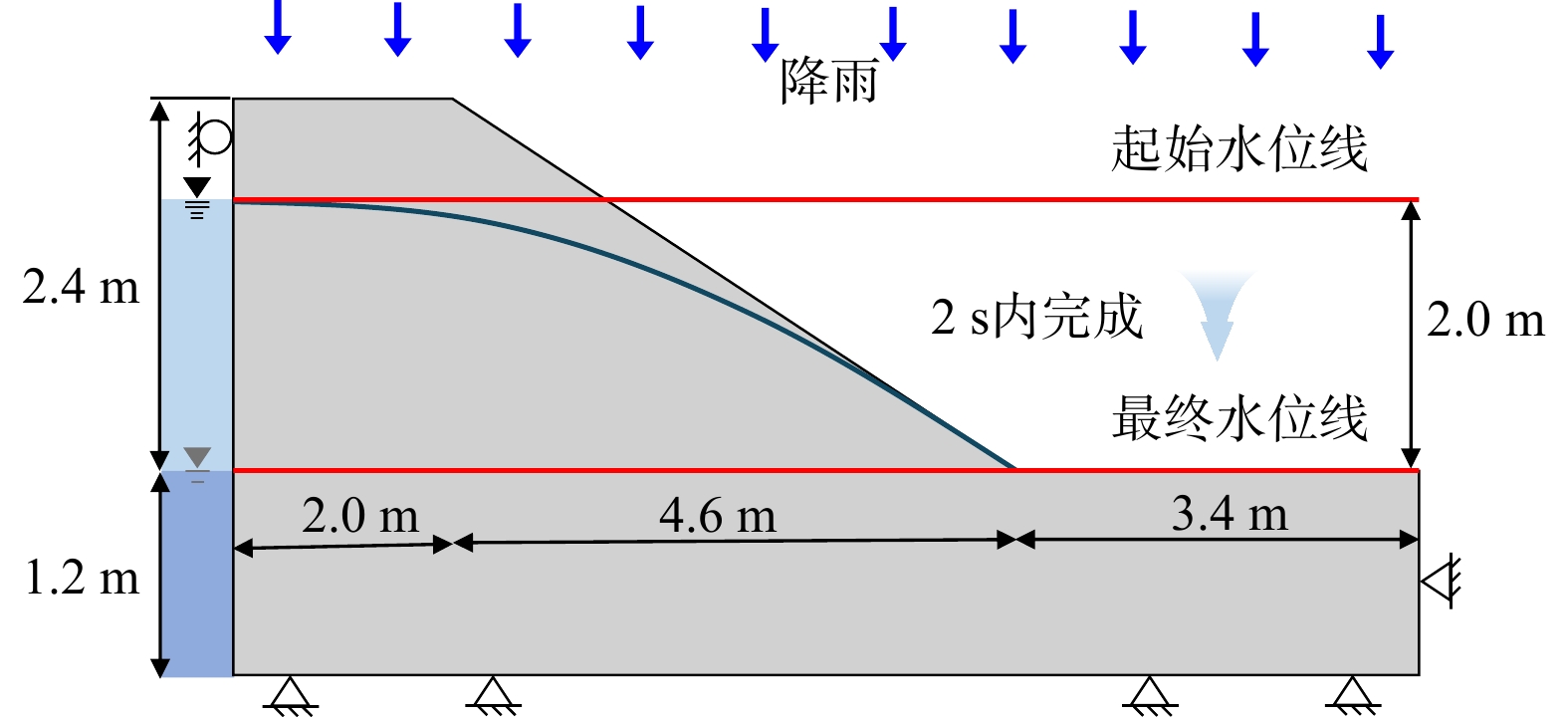
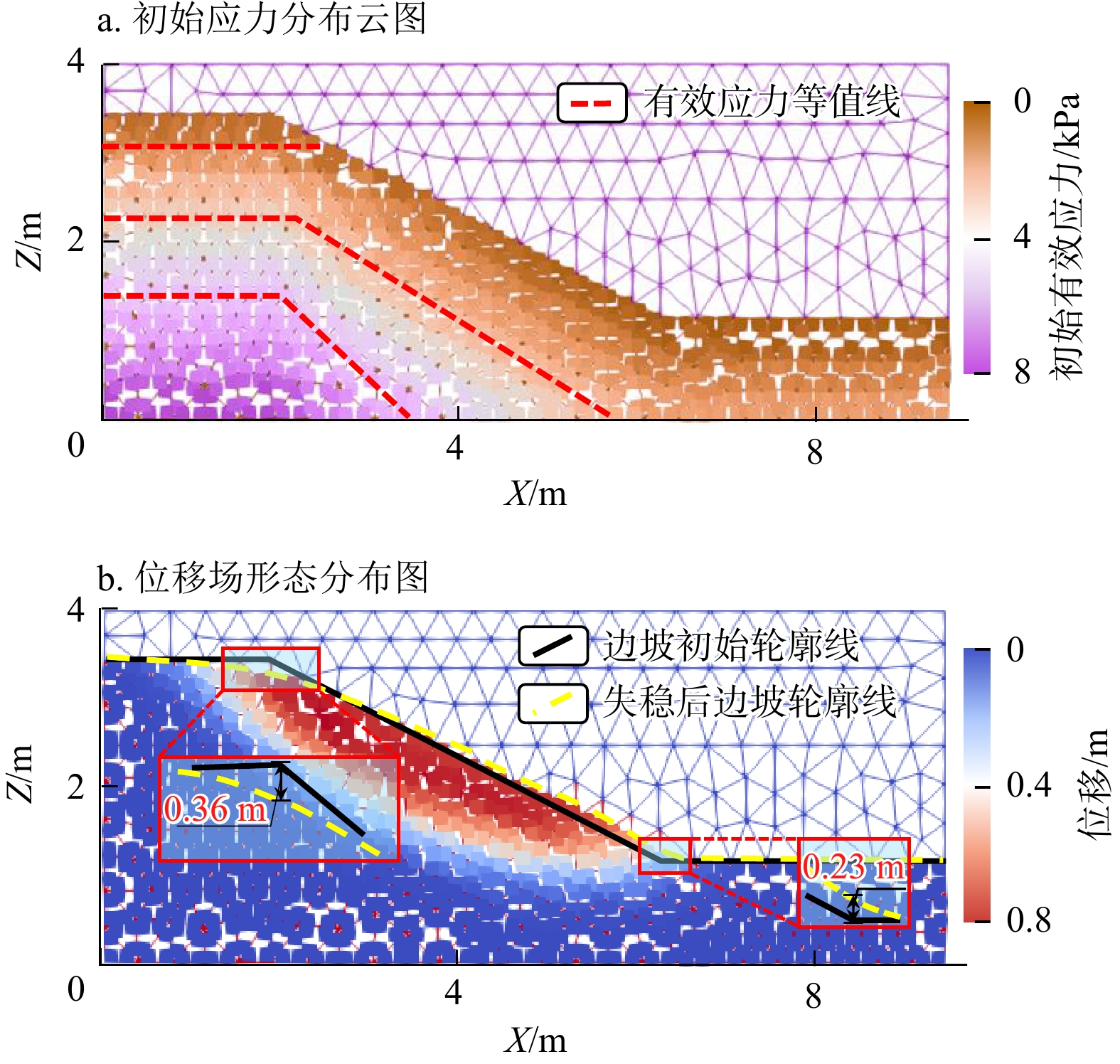
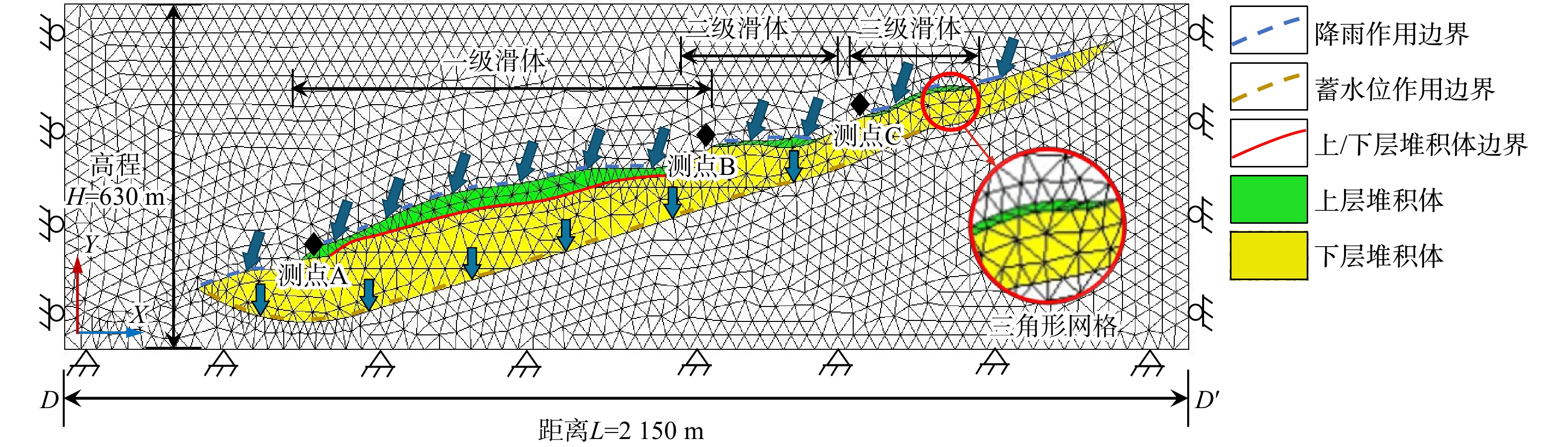
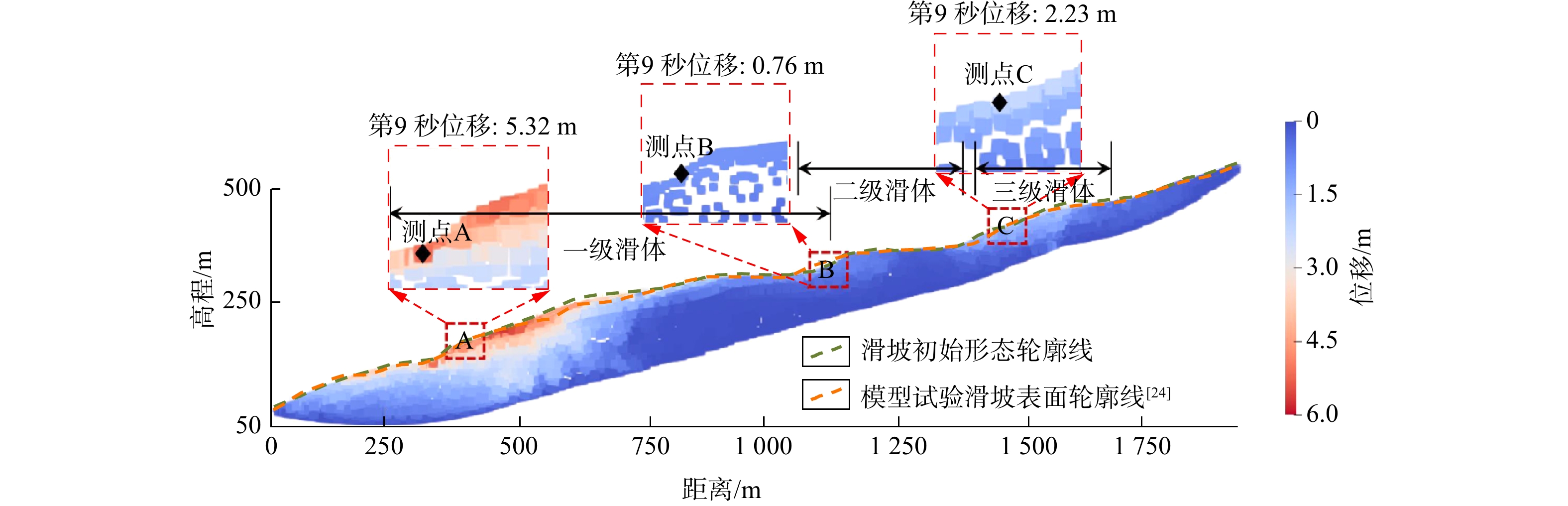
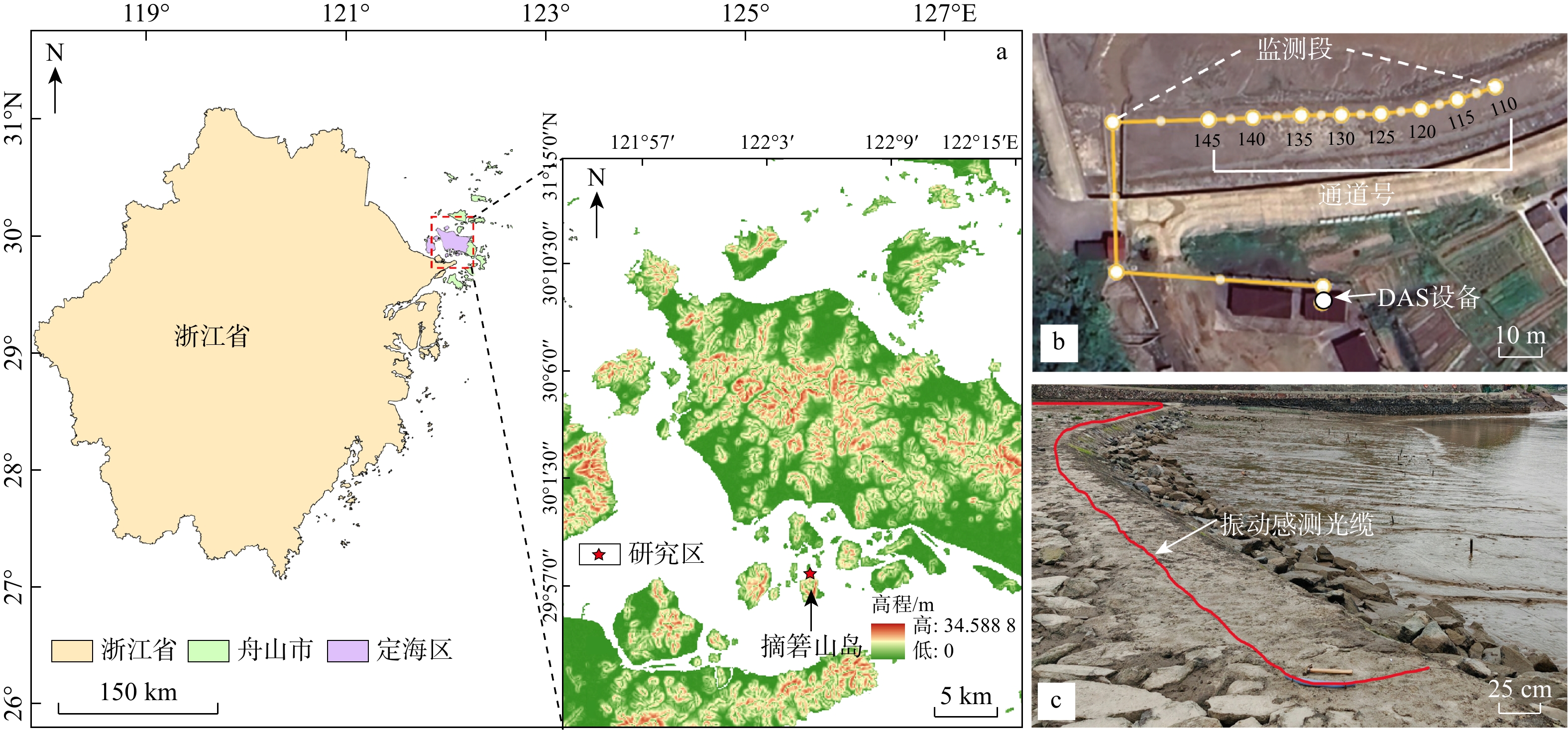
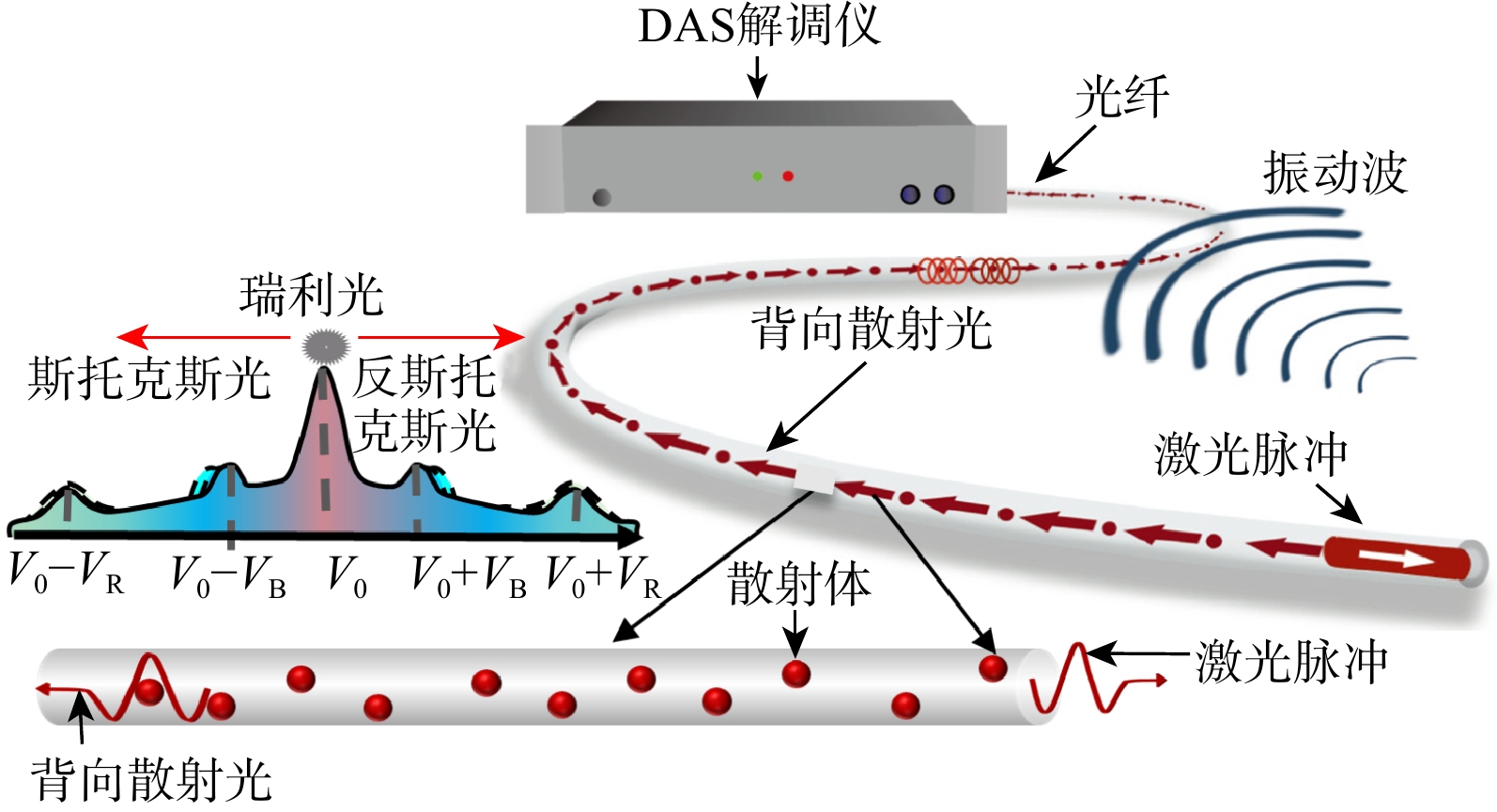
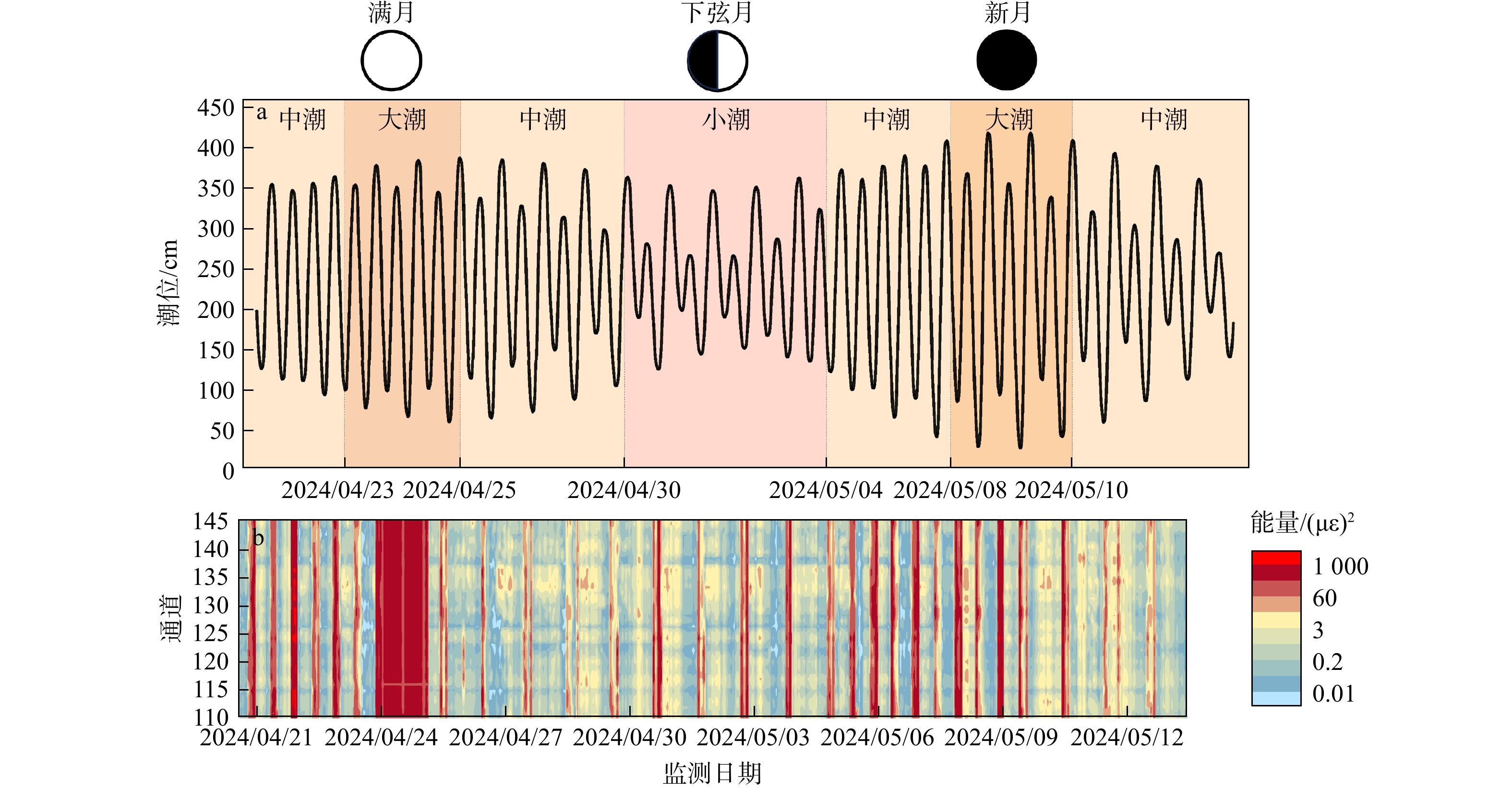
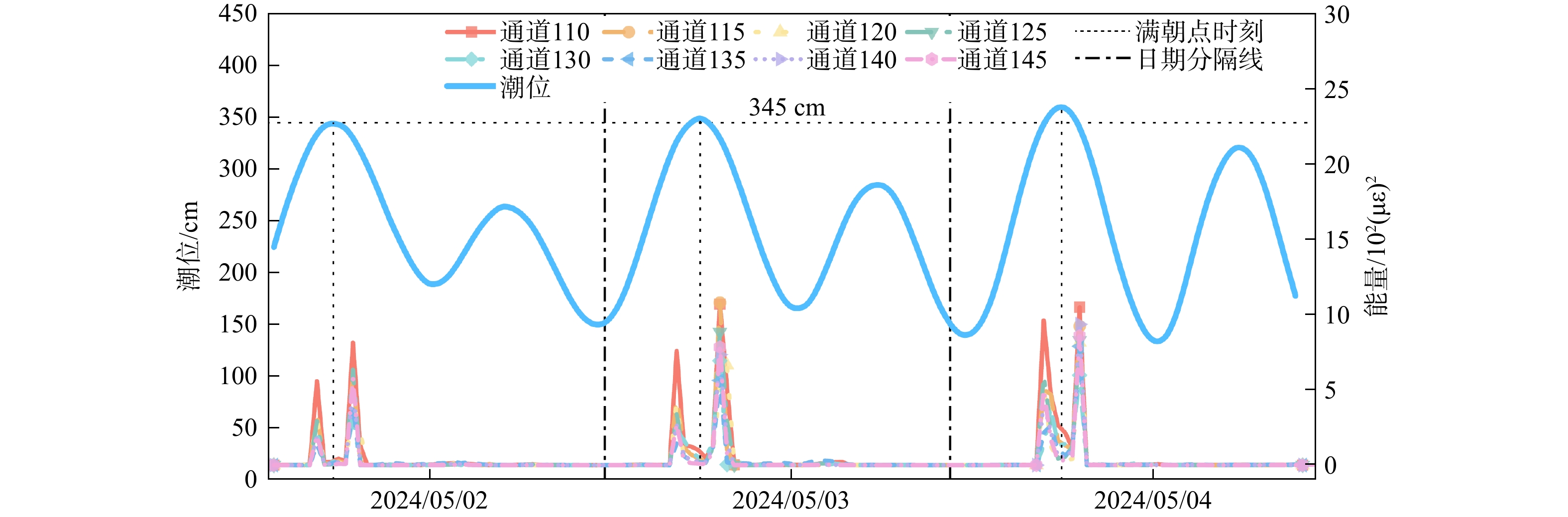
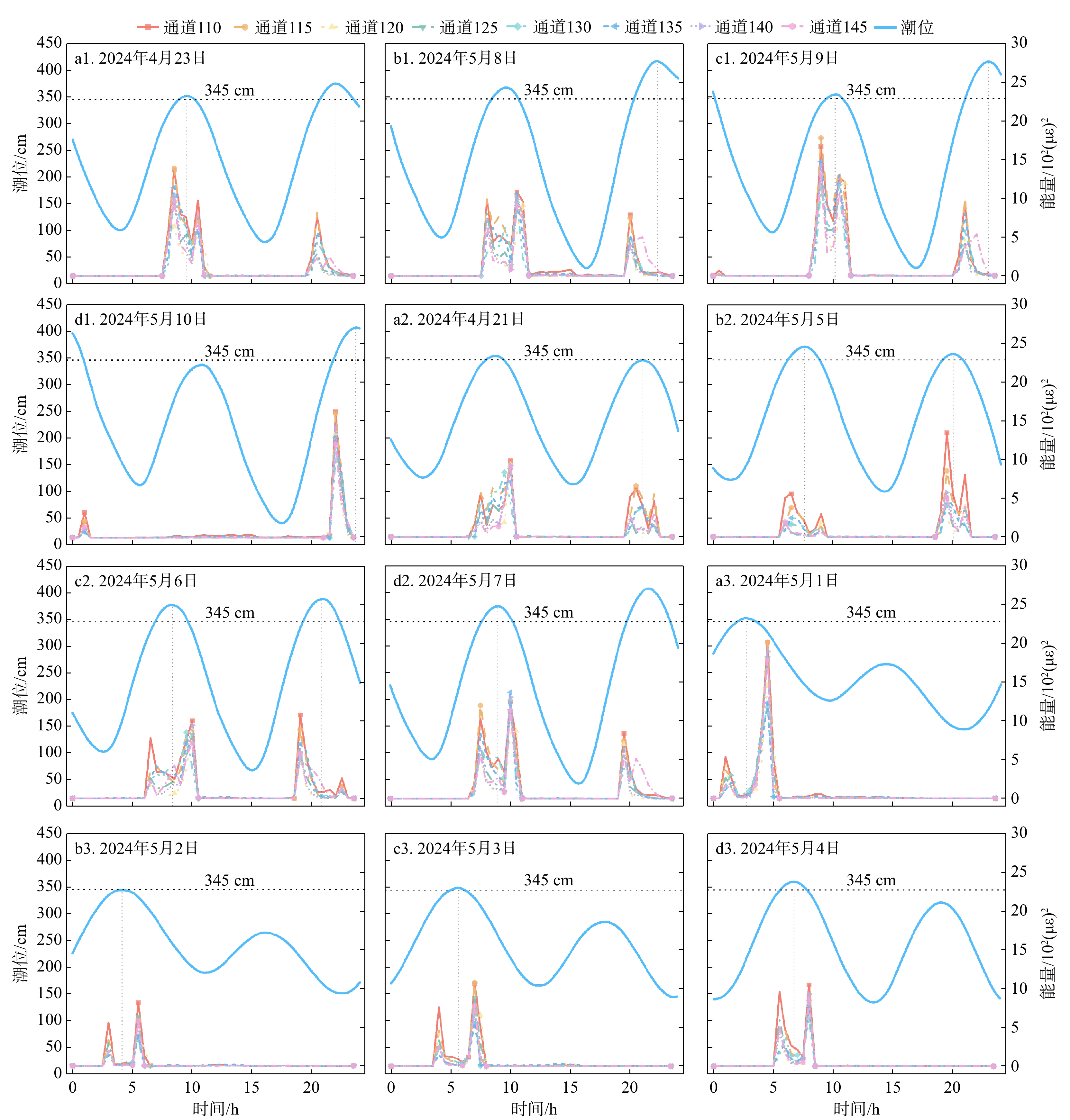
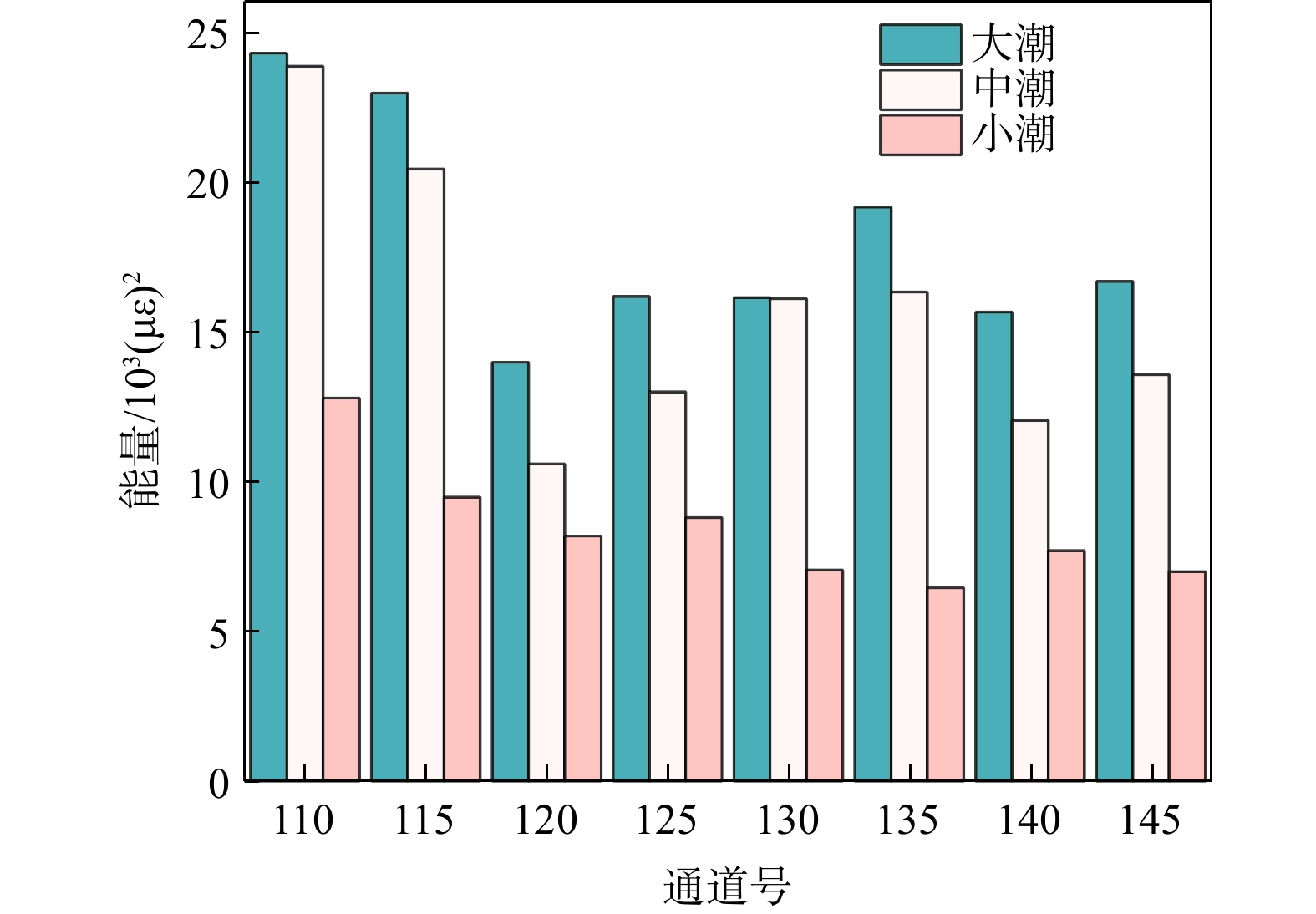
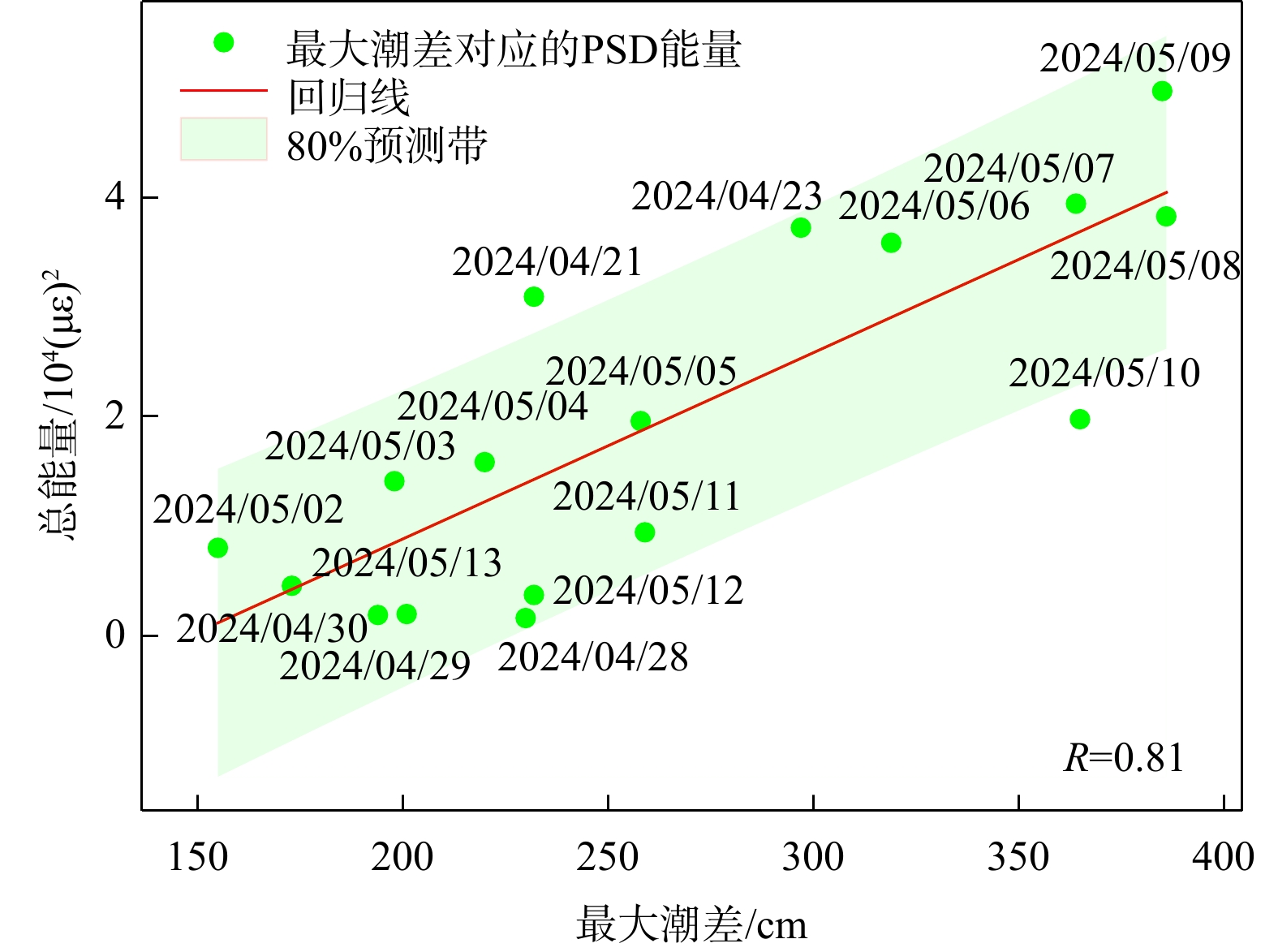
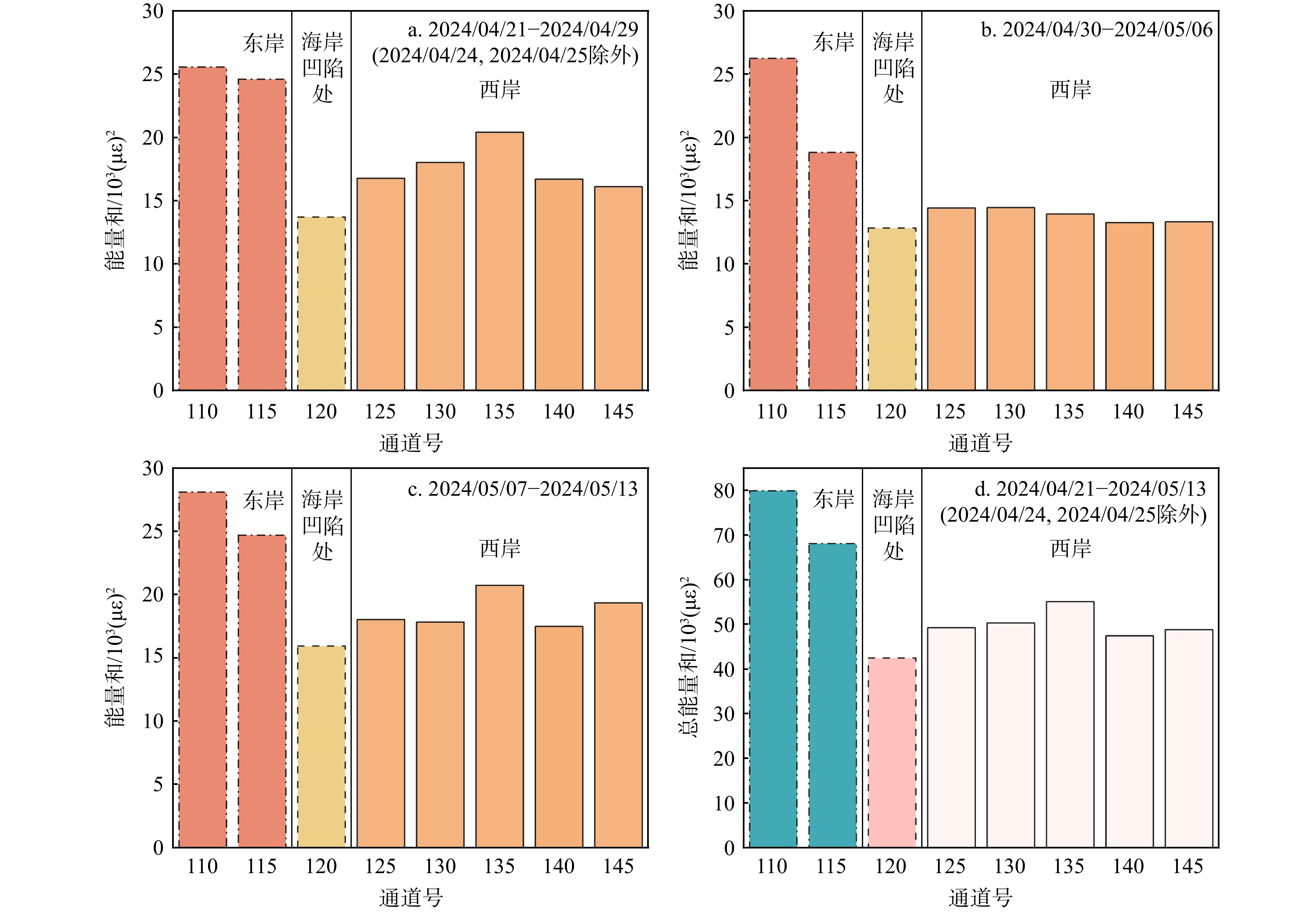
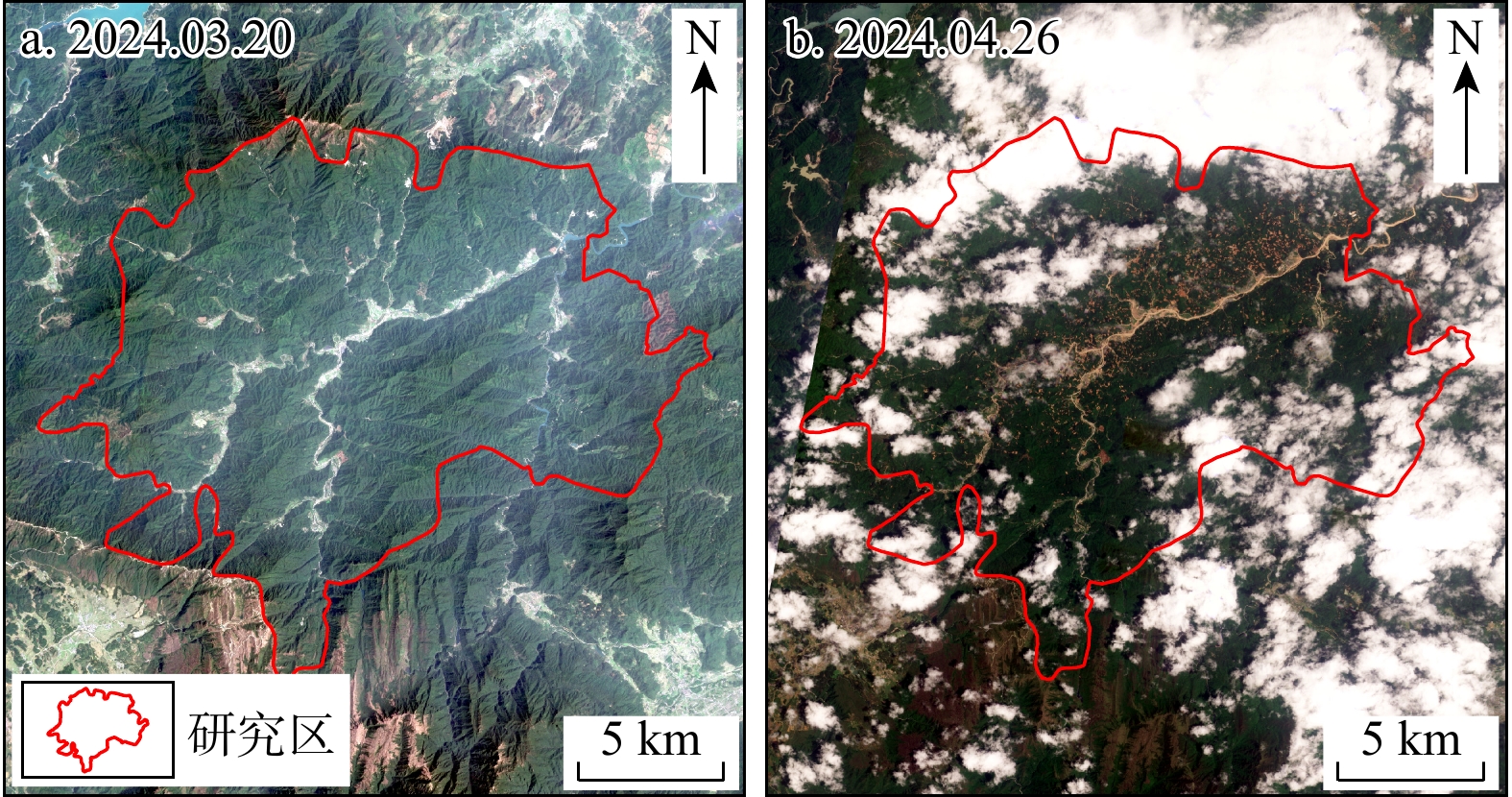
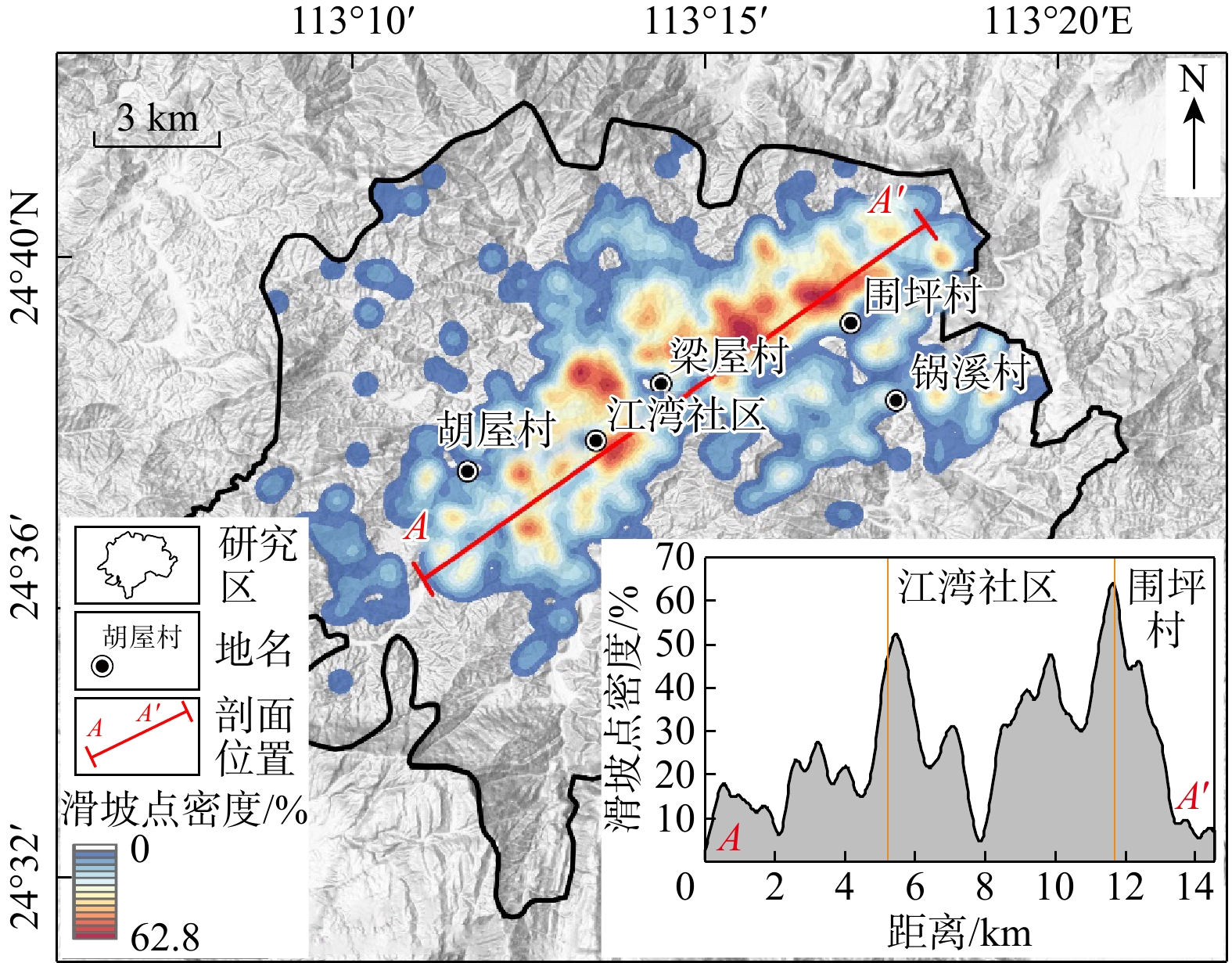
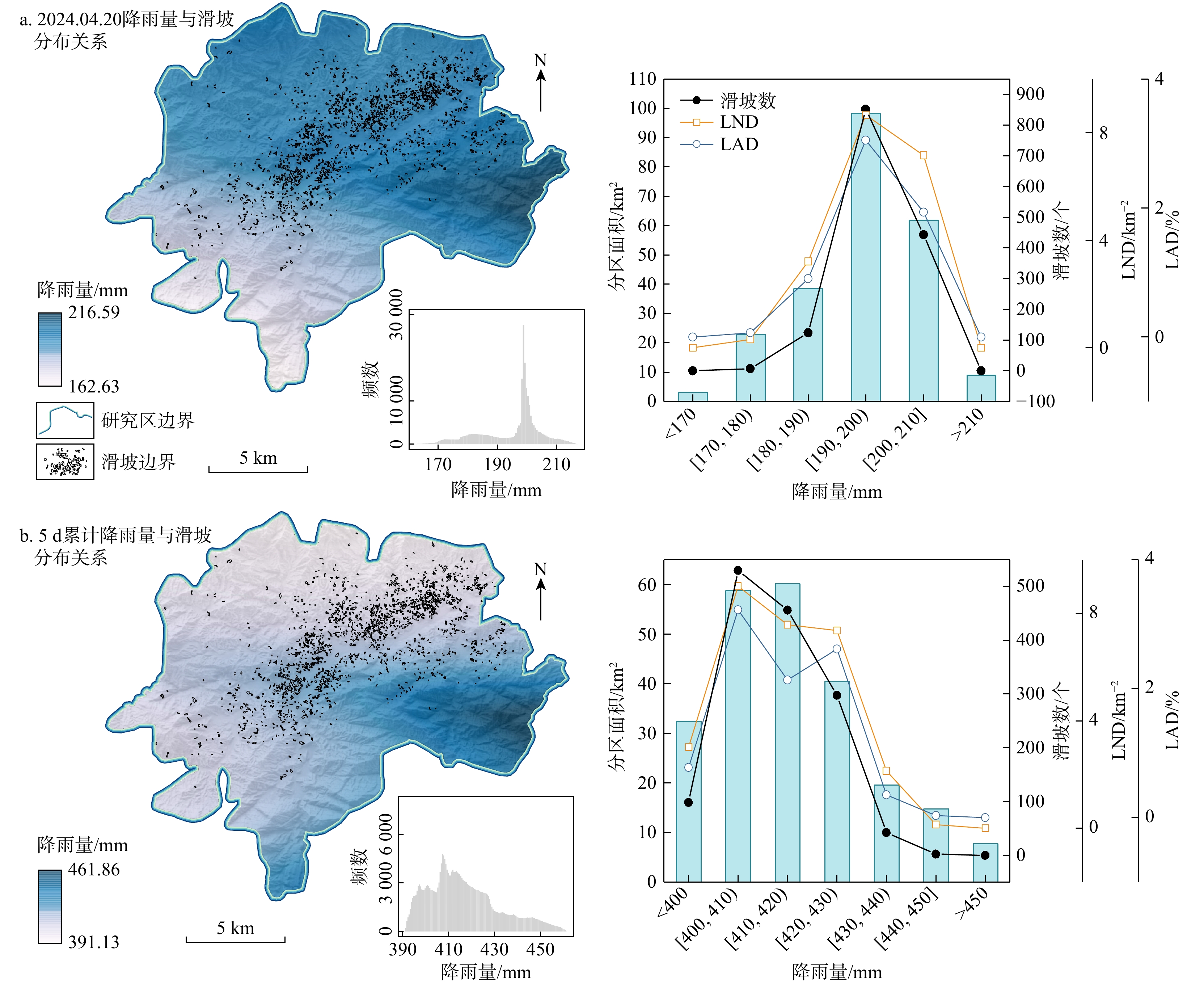
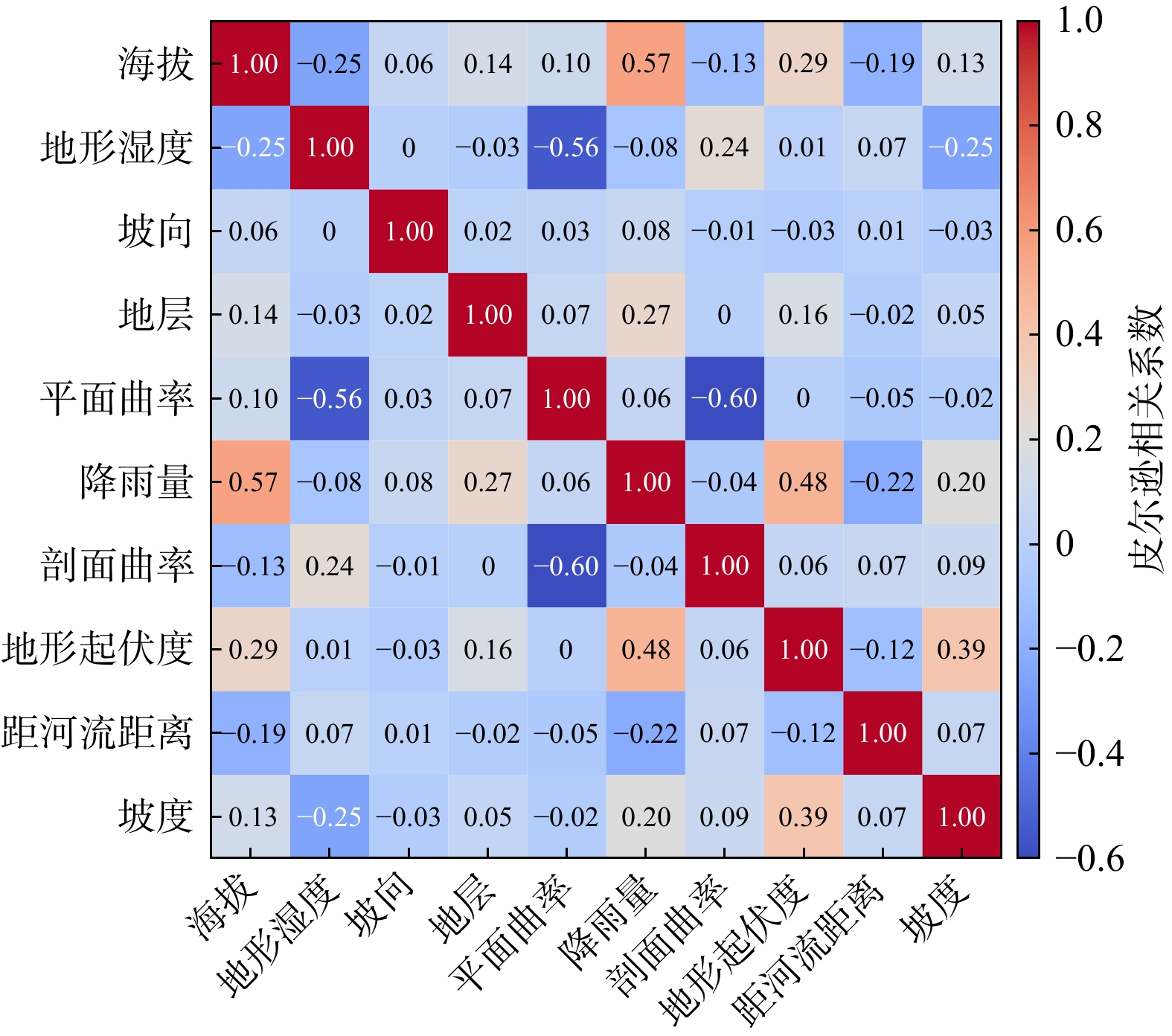
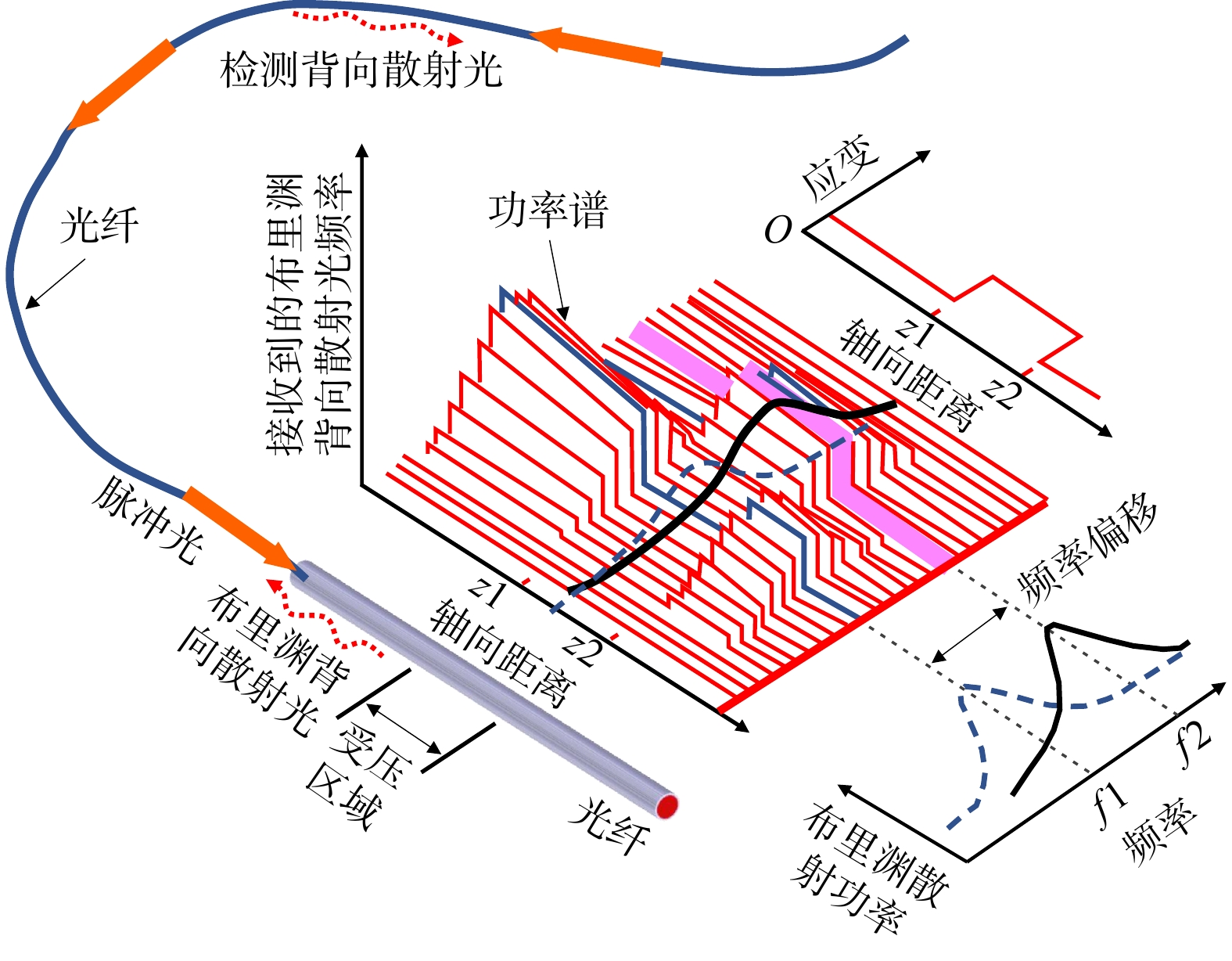
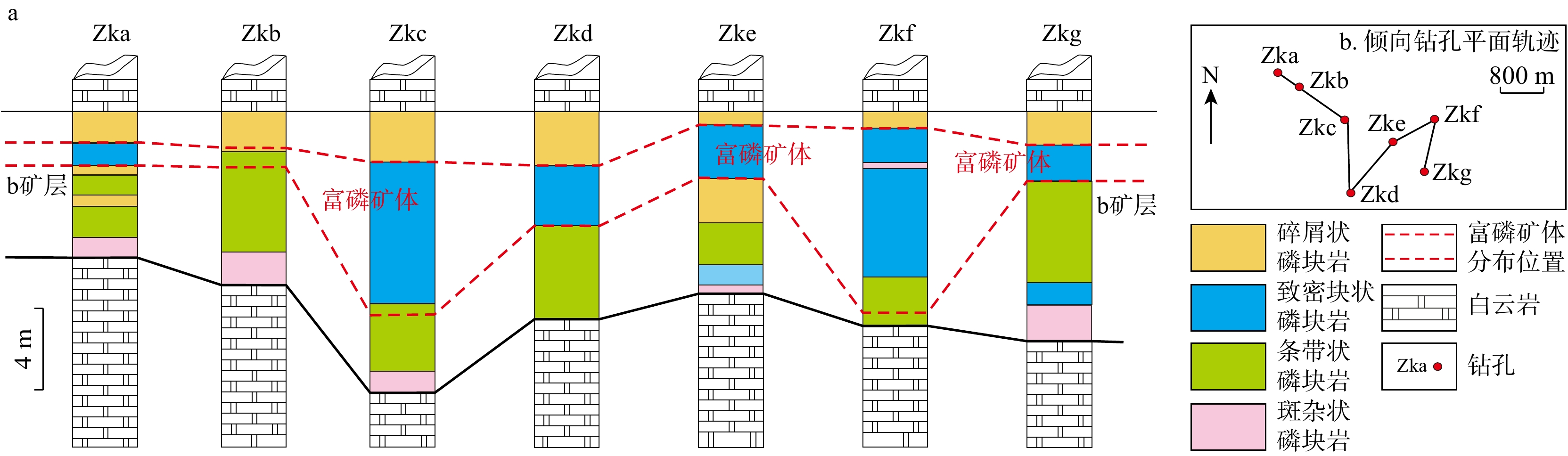
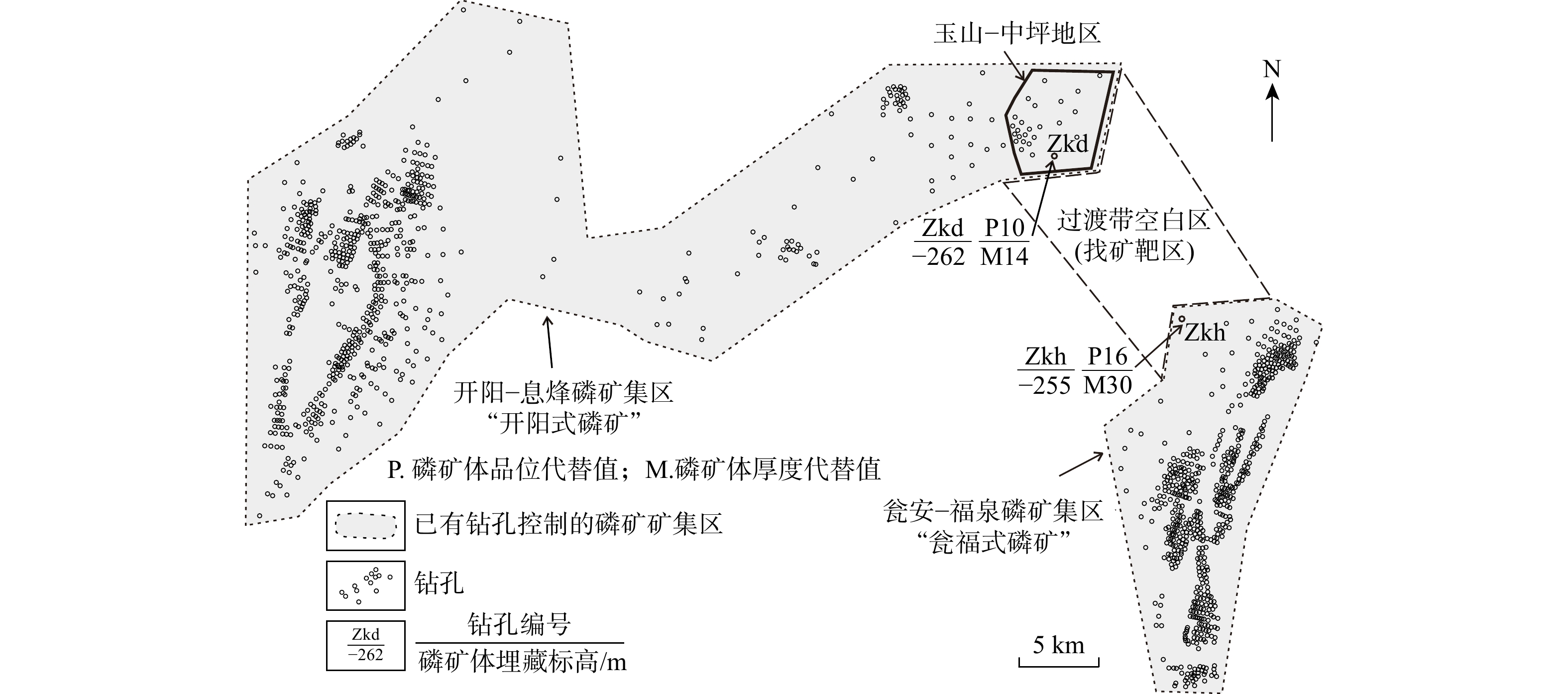
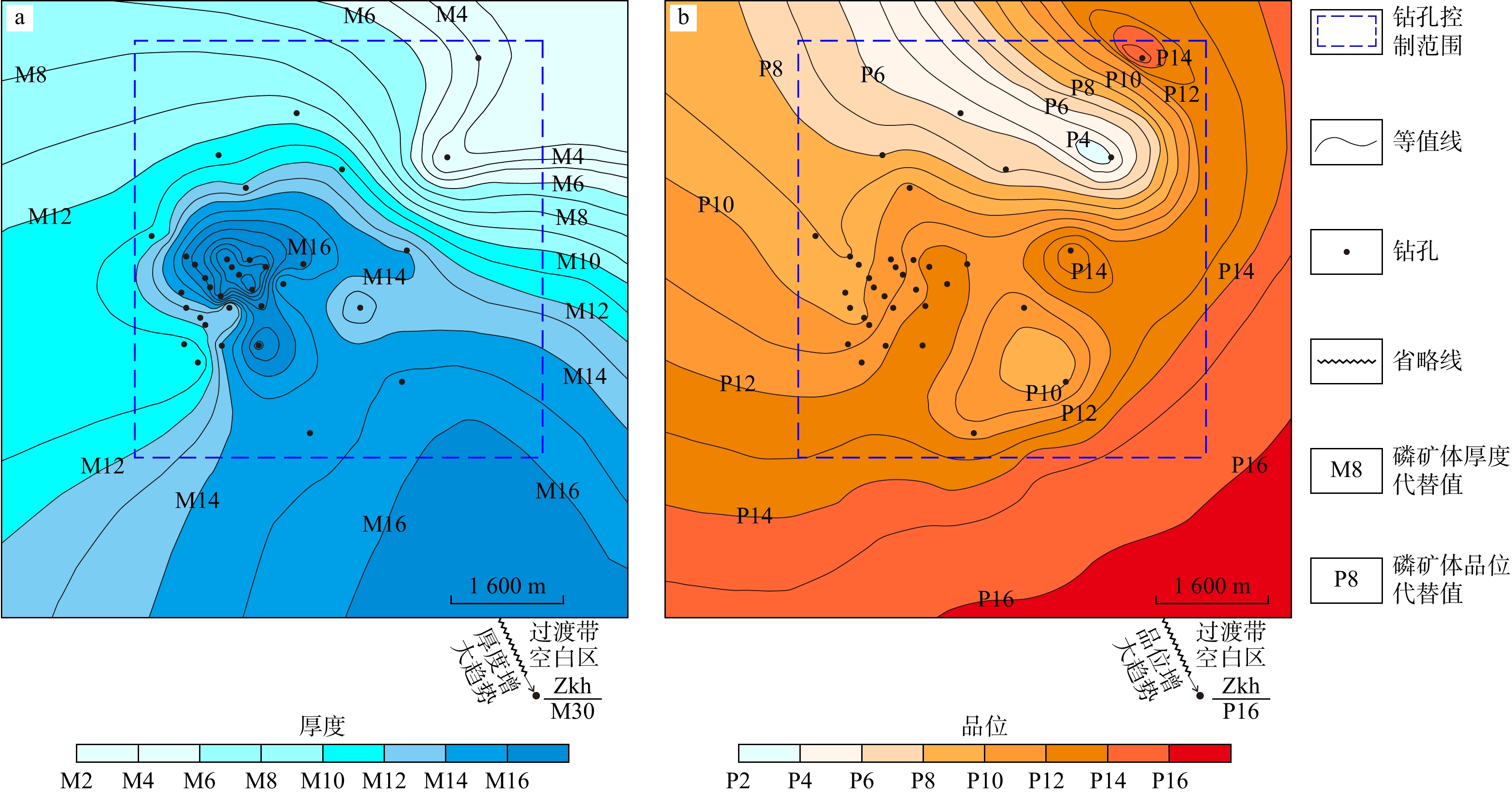
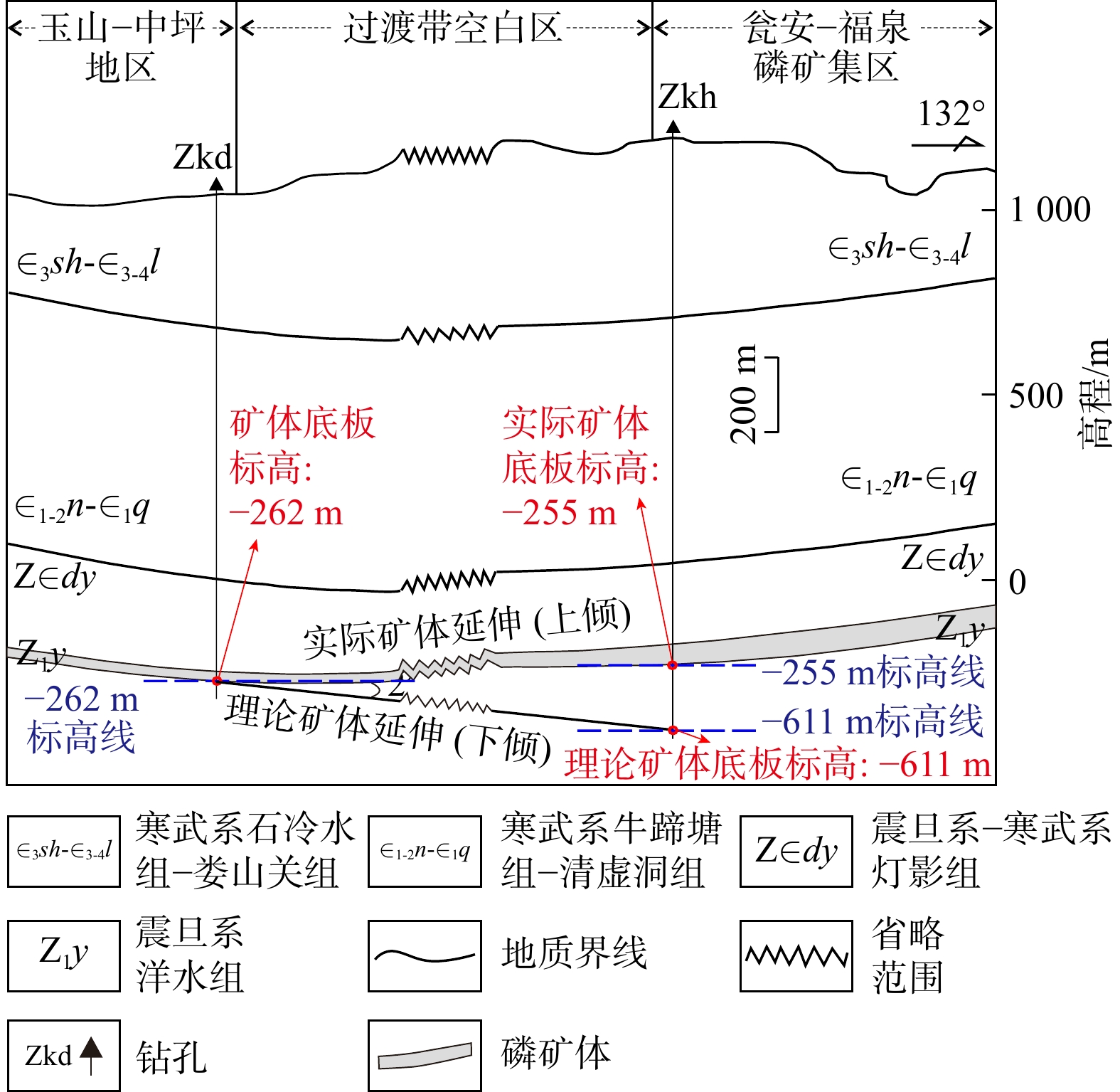
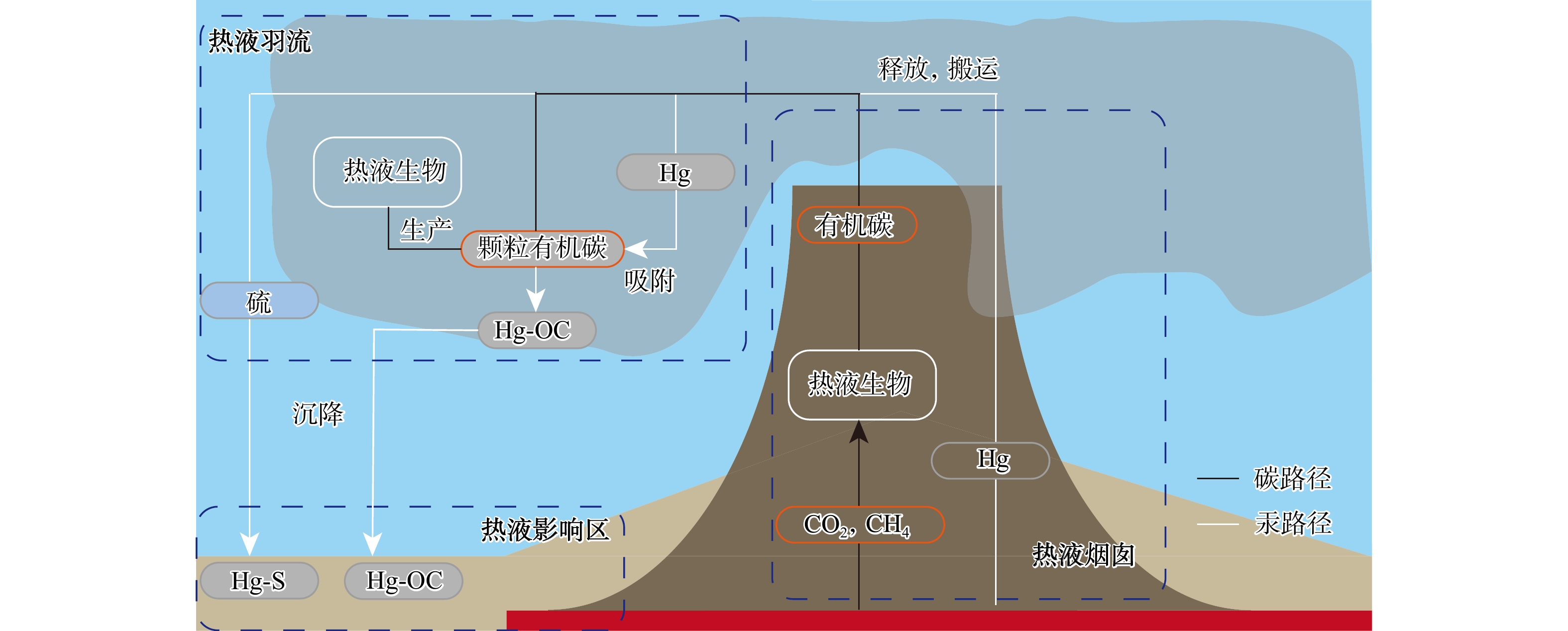
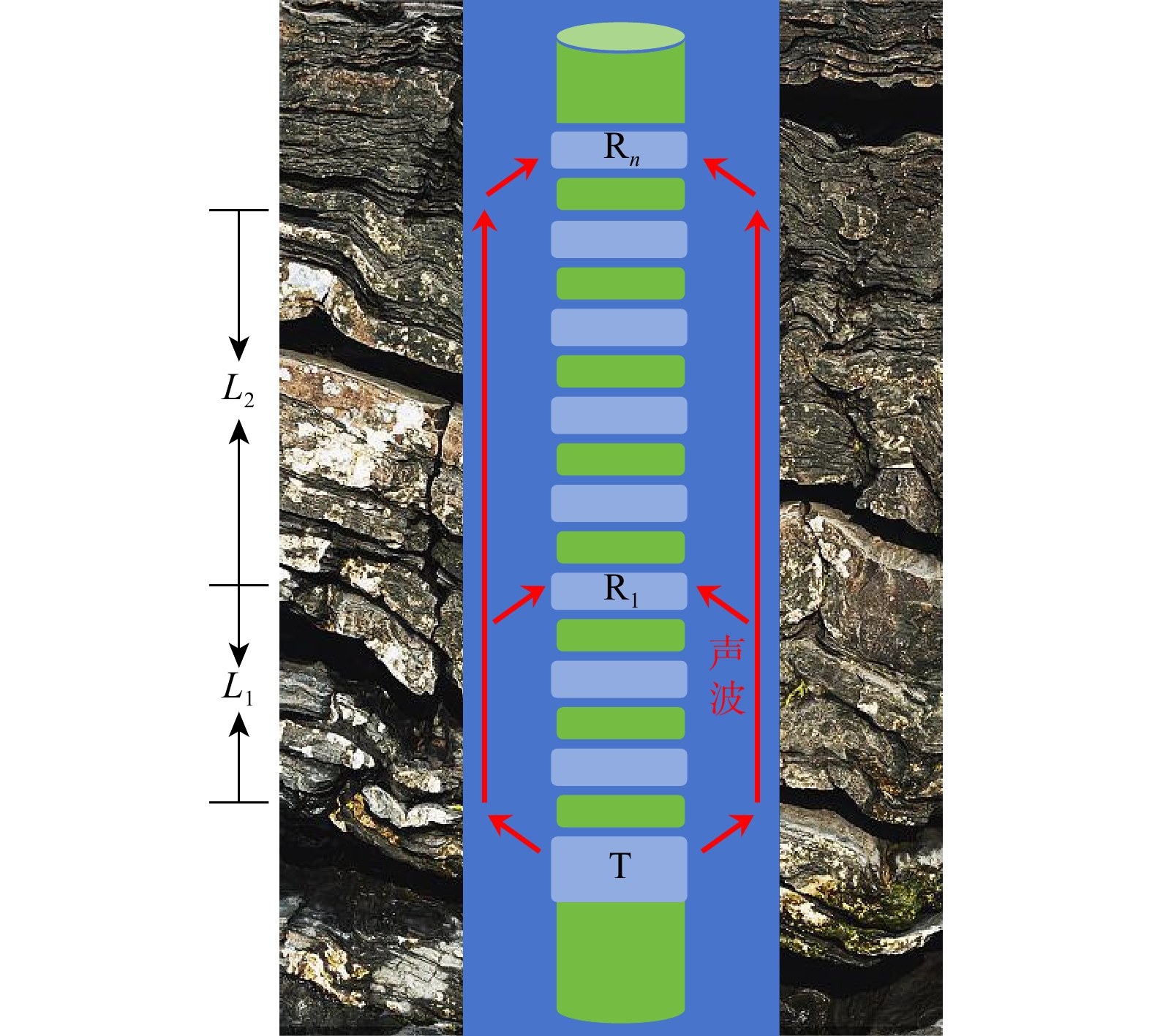
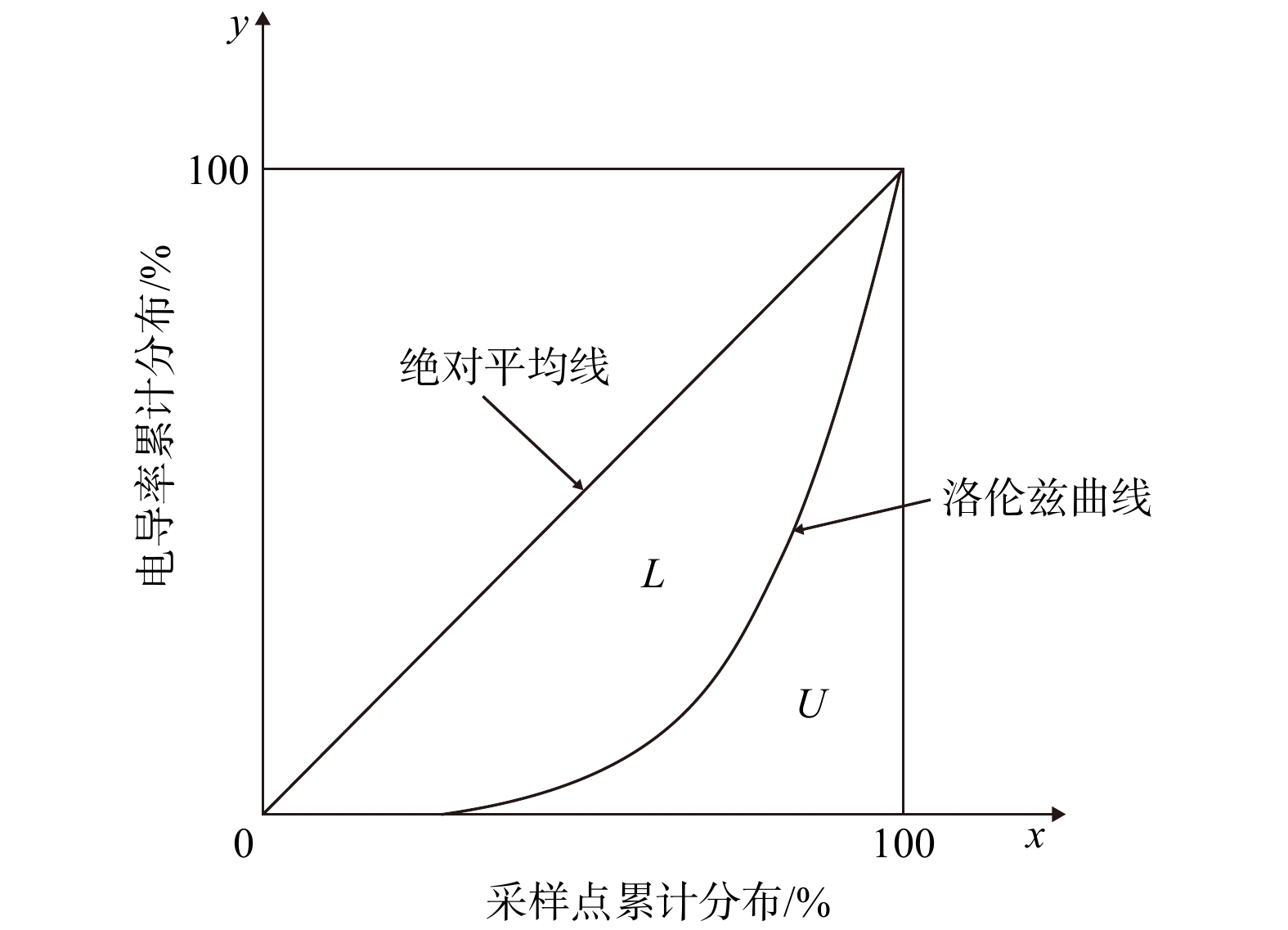
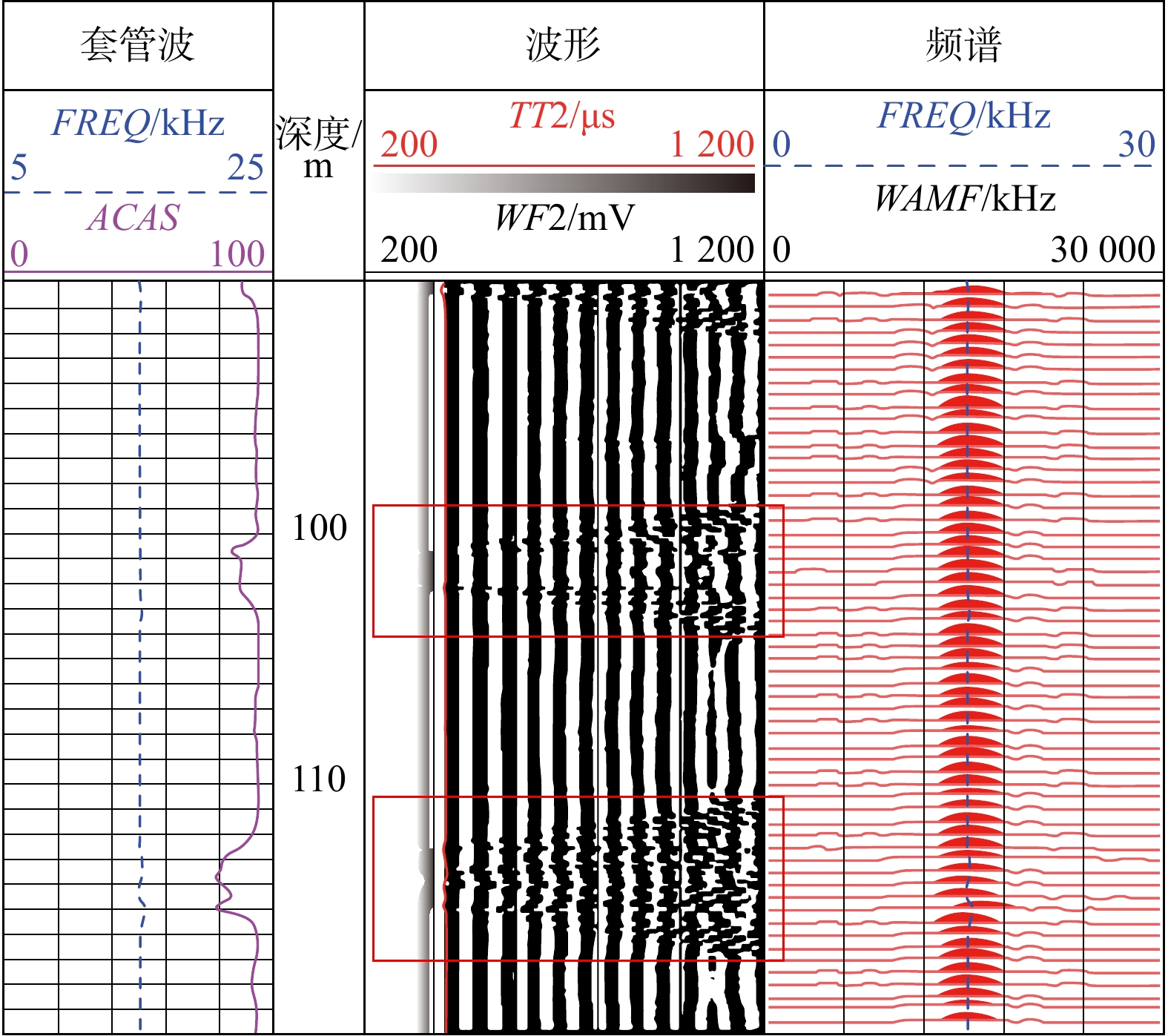
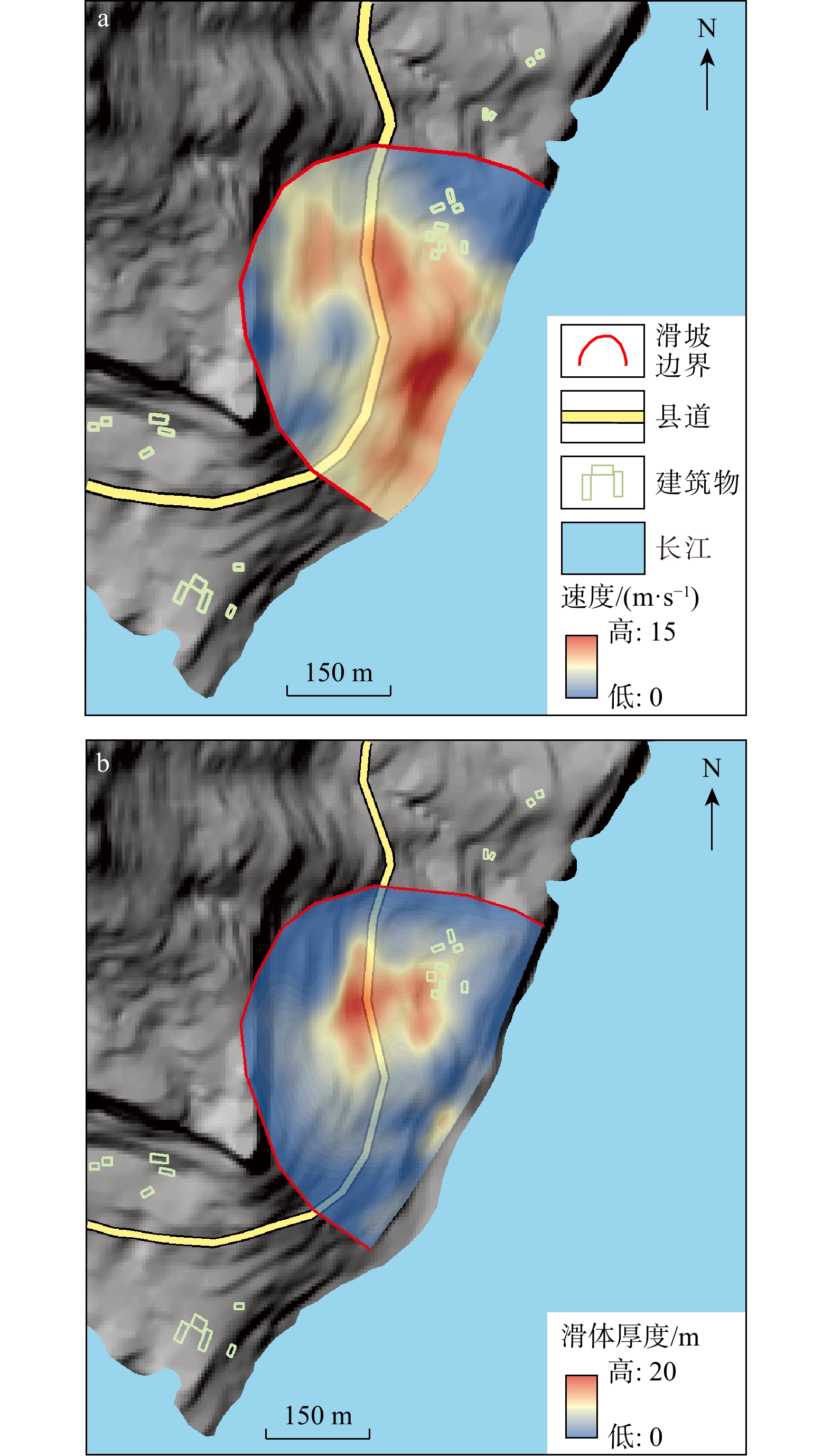
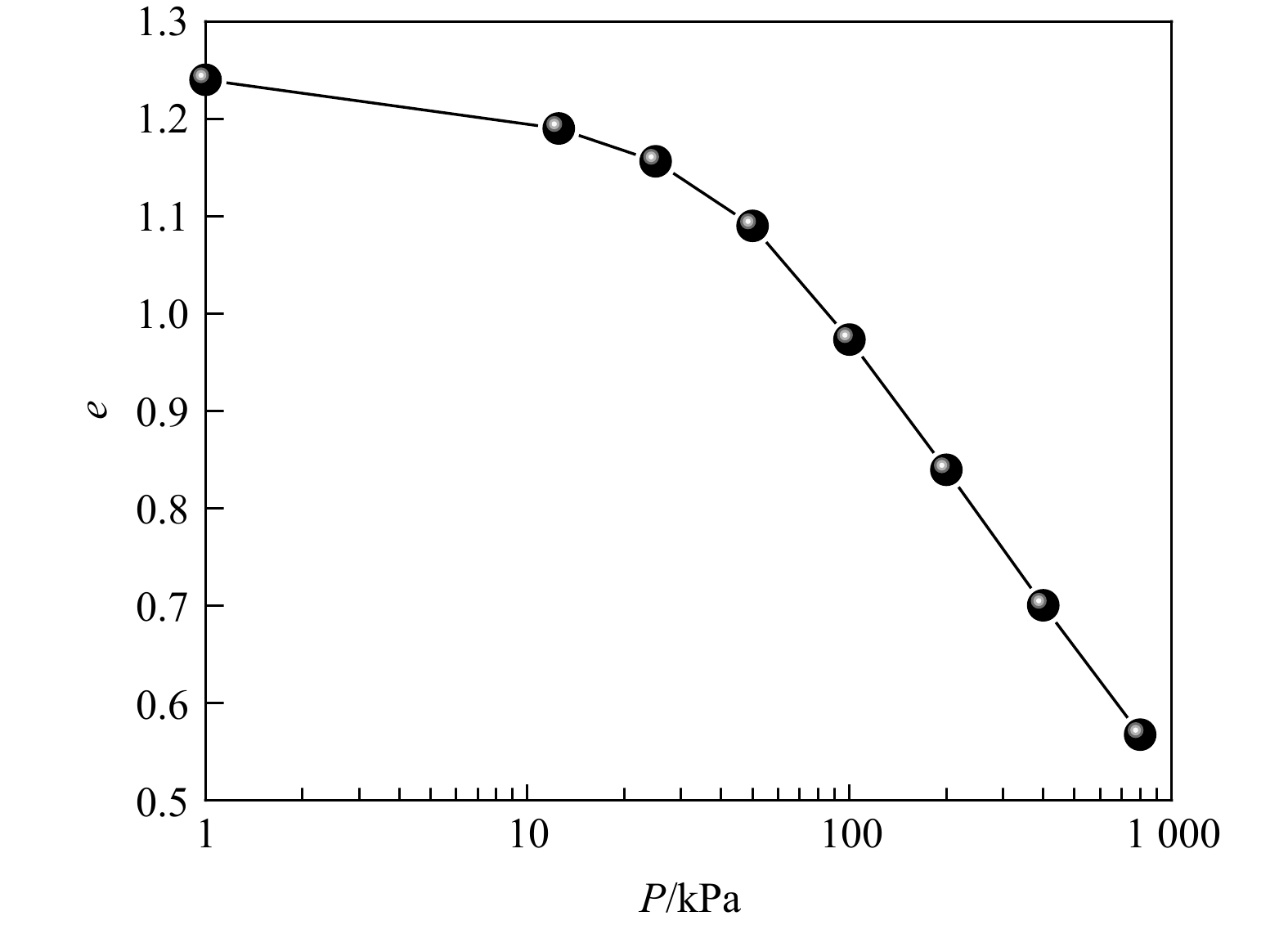
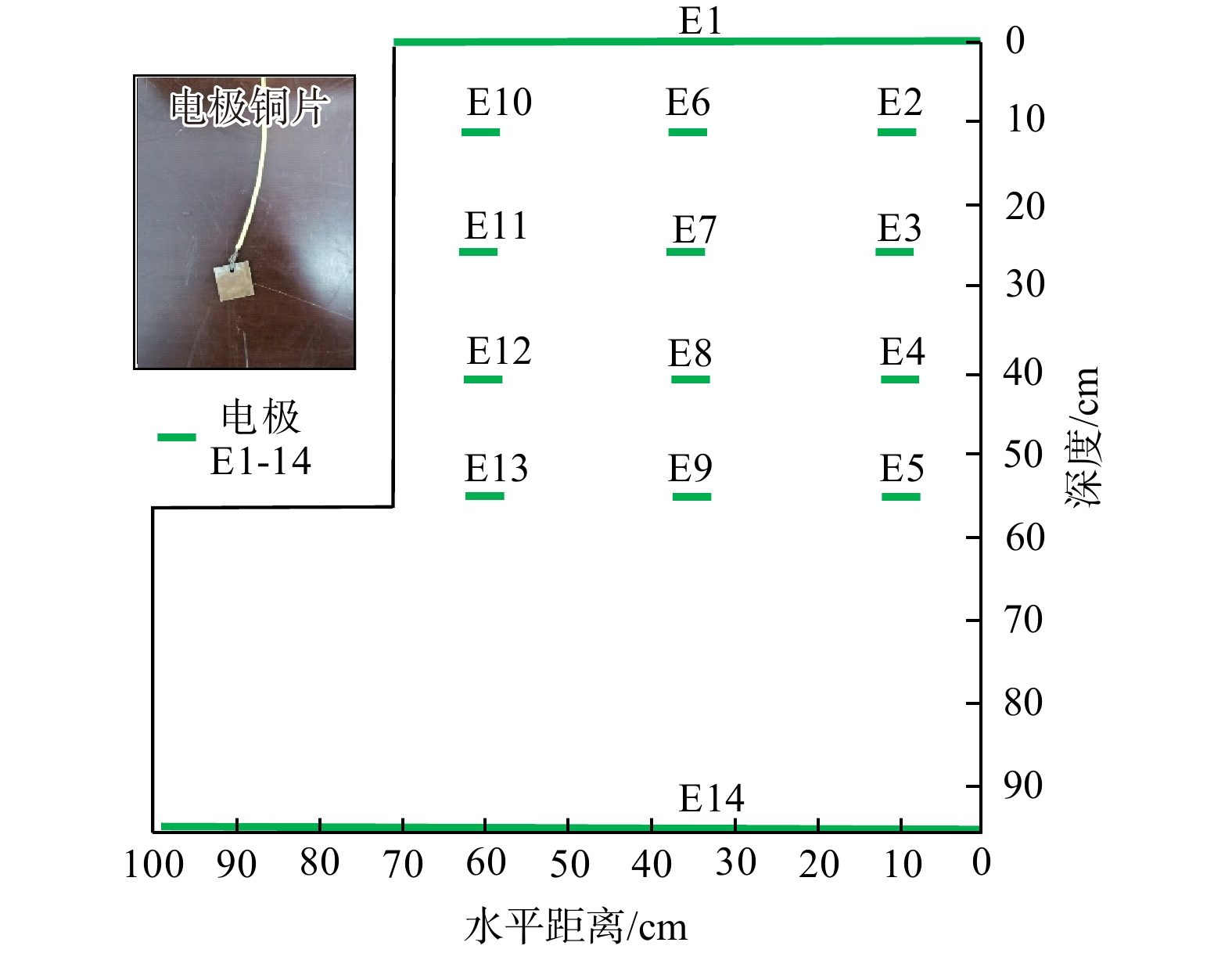
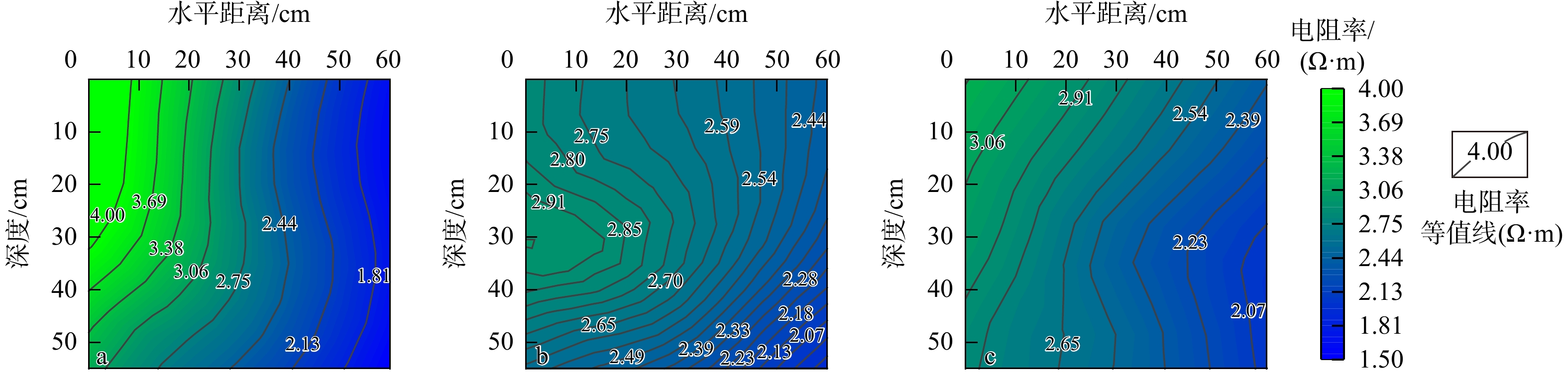
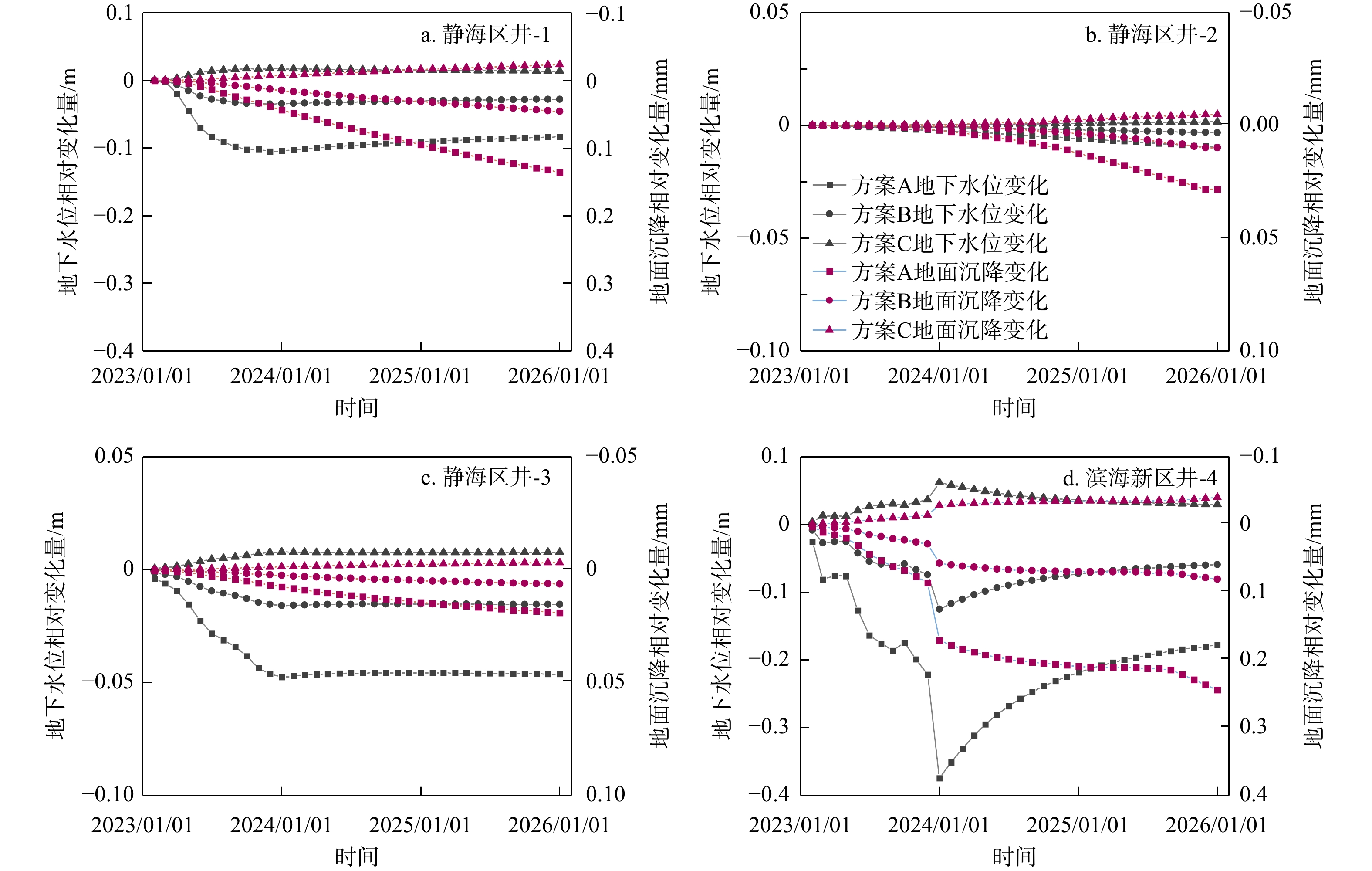
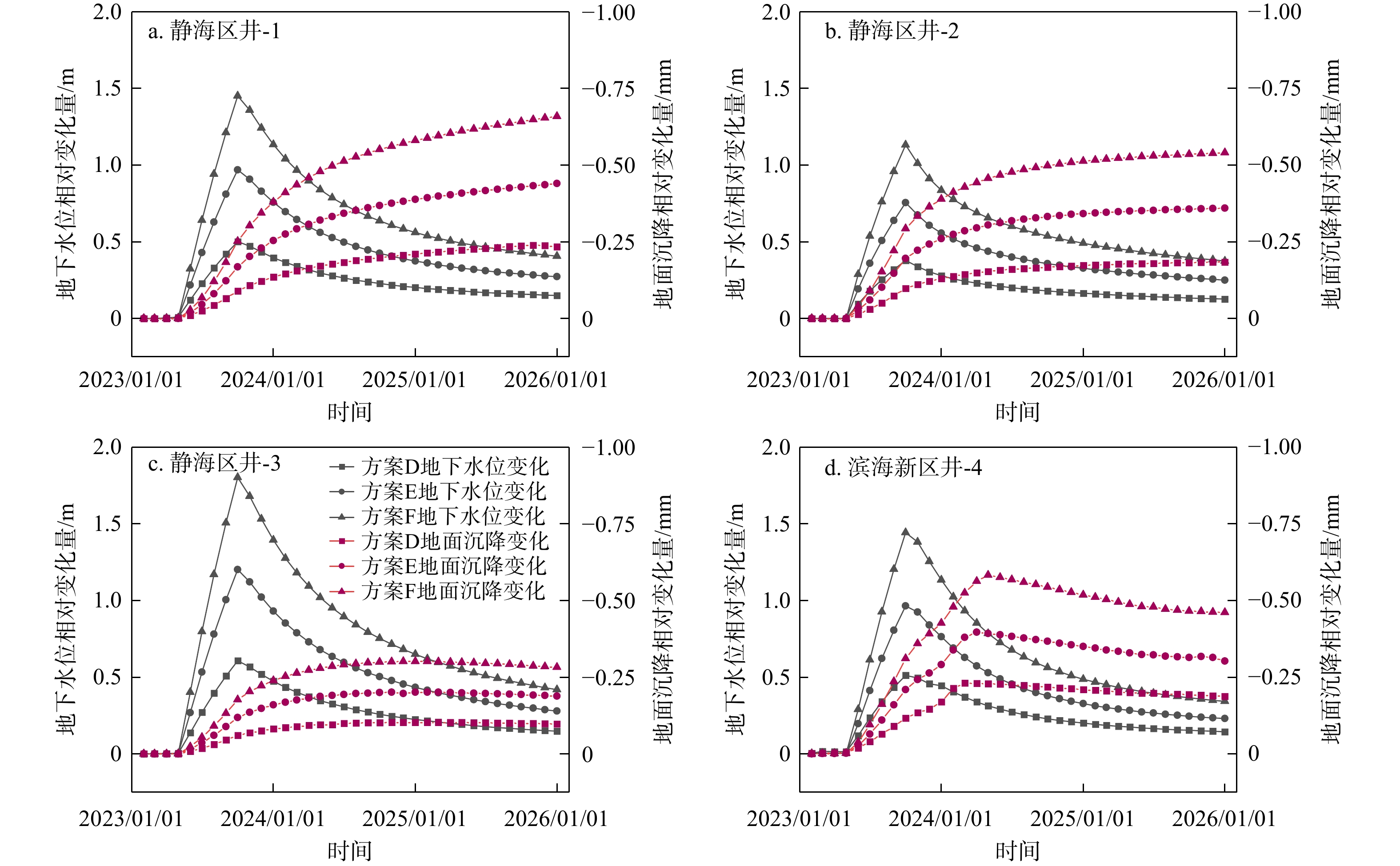
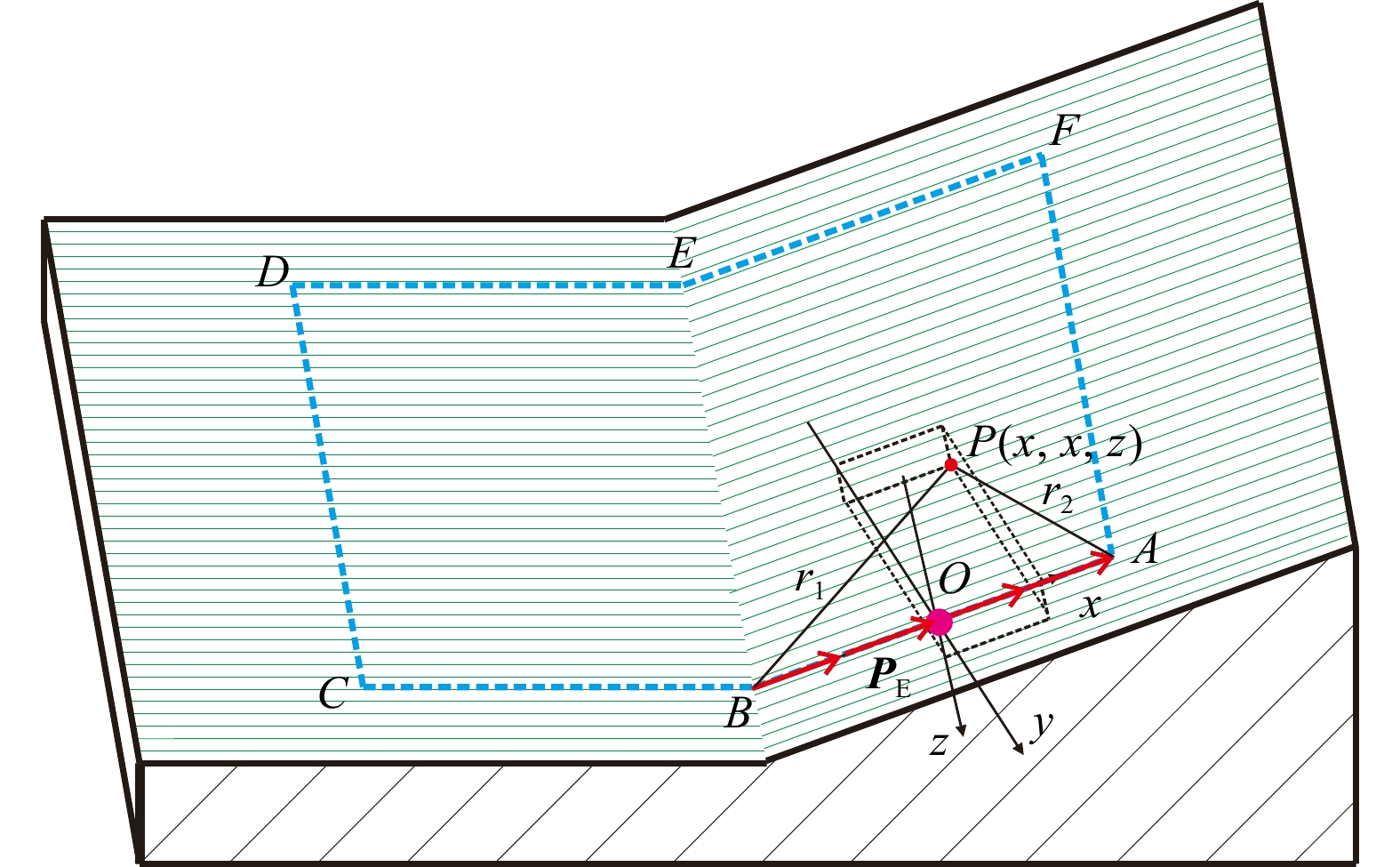
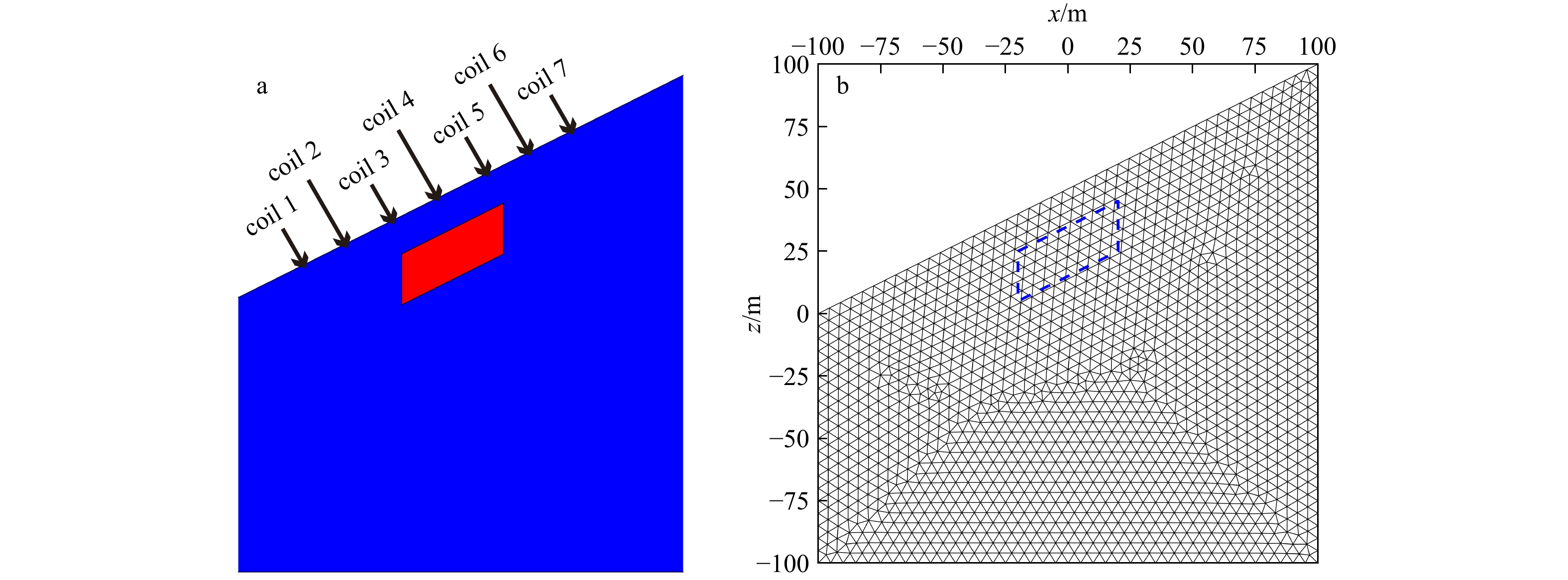
SignificanceTunnels are indispensable components of urban underground transportation systems, and their structural safety and service stability are closely related to the safety of transportation networks and other critical infrastructure. With the rapid development of urban rail transit, highway tunnels, and mountain tunnels, many tunnel structures are constructed and operated in increasingly complex geological, hydrological, and environmental conditions. During long-term service, tunnels are subjected to surrounding rock pressure, groundwater action, construction disturbance, material deterioration, and cyclic loading, which may lead to cracking, lining deformation, local stress concentration, and even structural damage. Therefore, long-term and continuous structural health monitoring is of great engineering significance for condition assessment, damage diagnosis, risk warning, and maintenance decision-making. As a typical distributed fiber optic sensing technology, Brillouin optical time-domain sensing (BOTDS) has the advantages of long monitoring distance, flexible deployment, strong immunity to electromagnetic interference, and good long-term stability, and has demonstrated significant potential in tunnel structural monitoring.
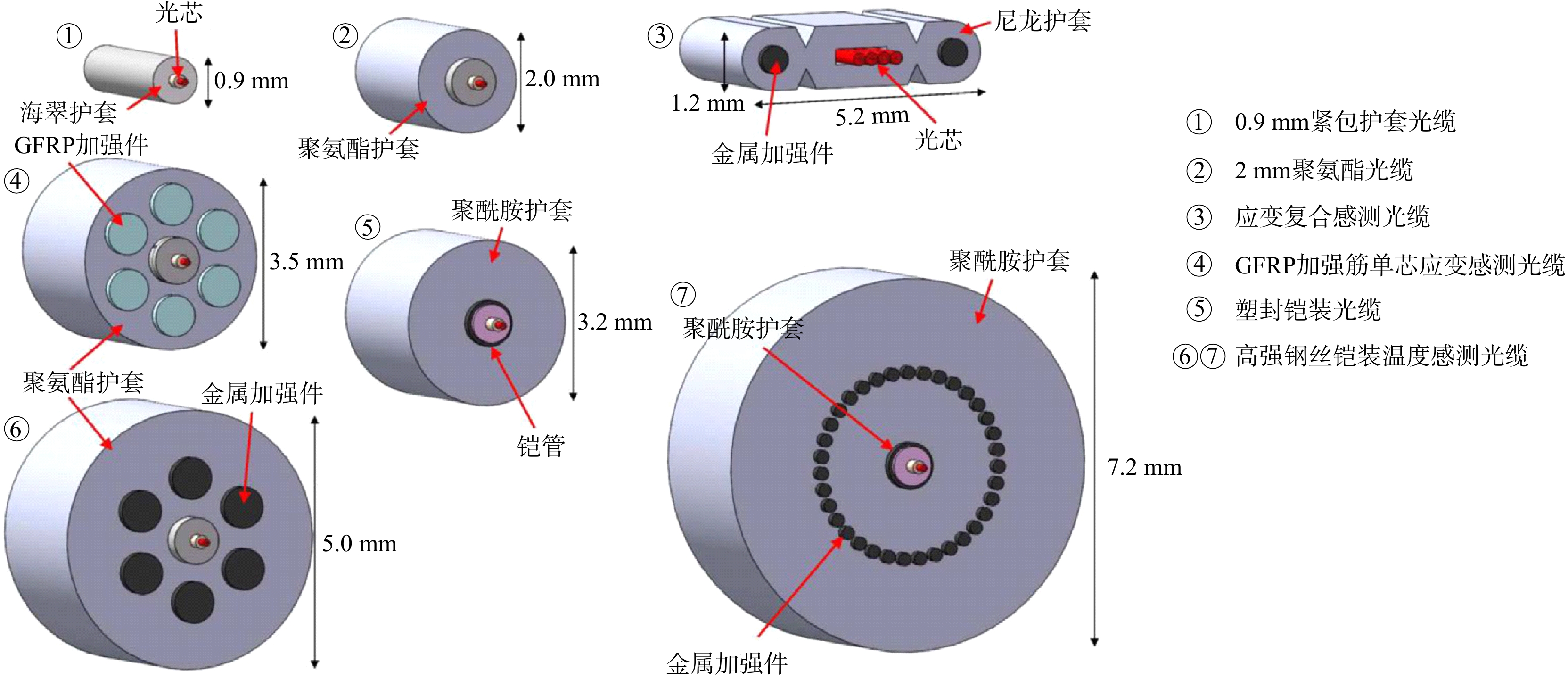
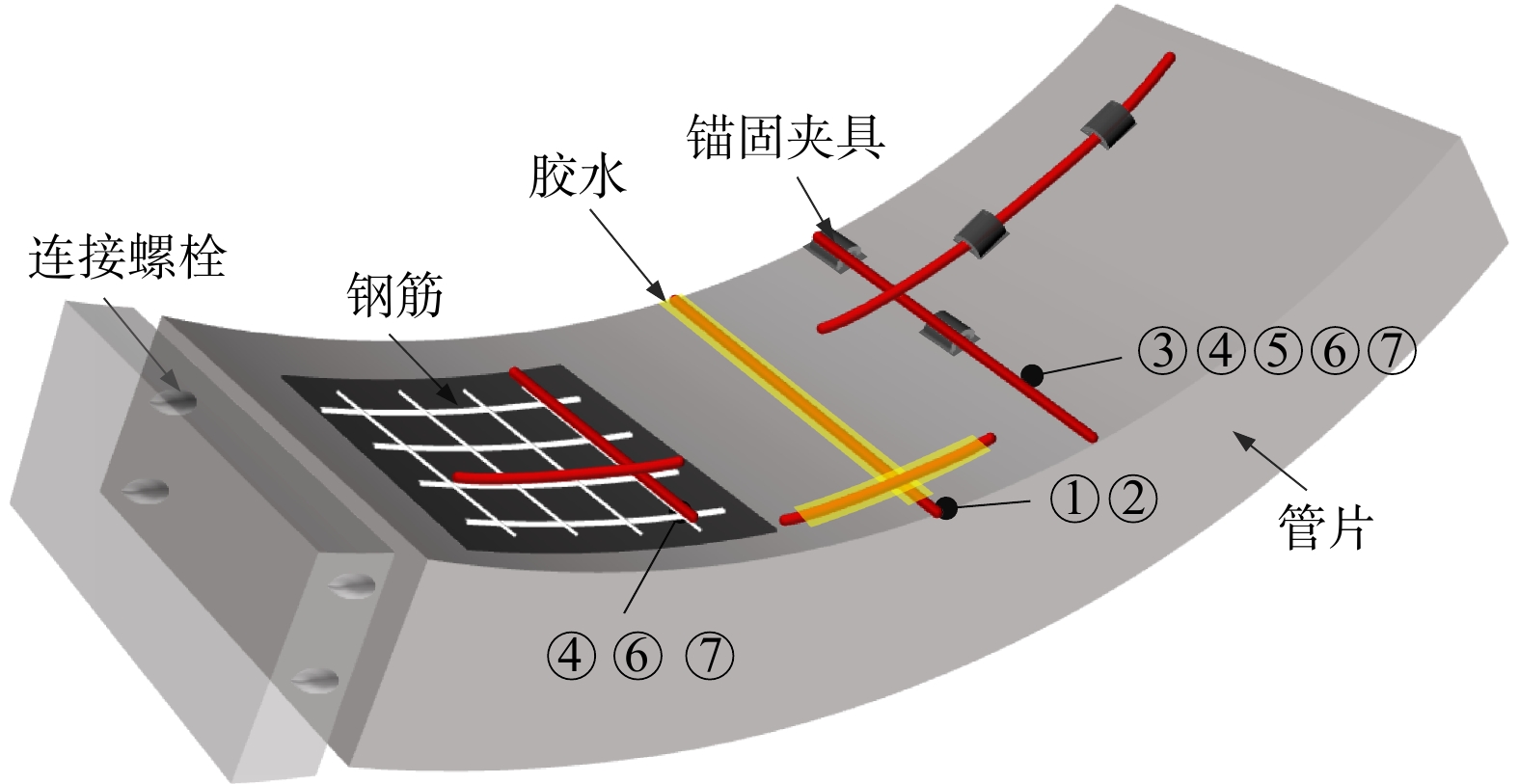
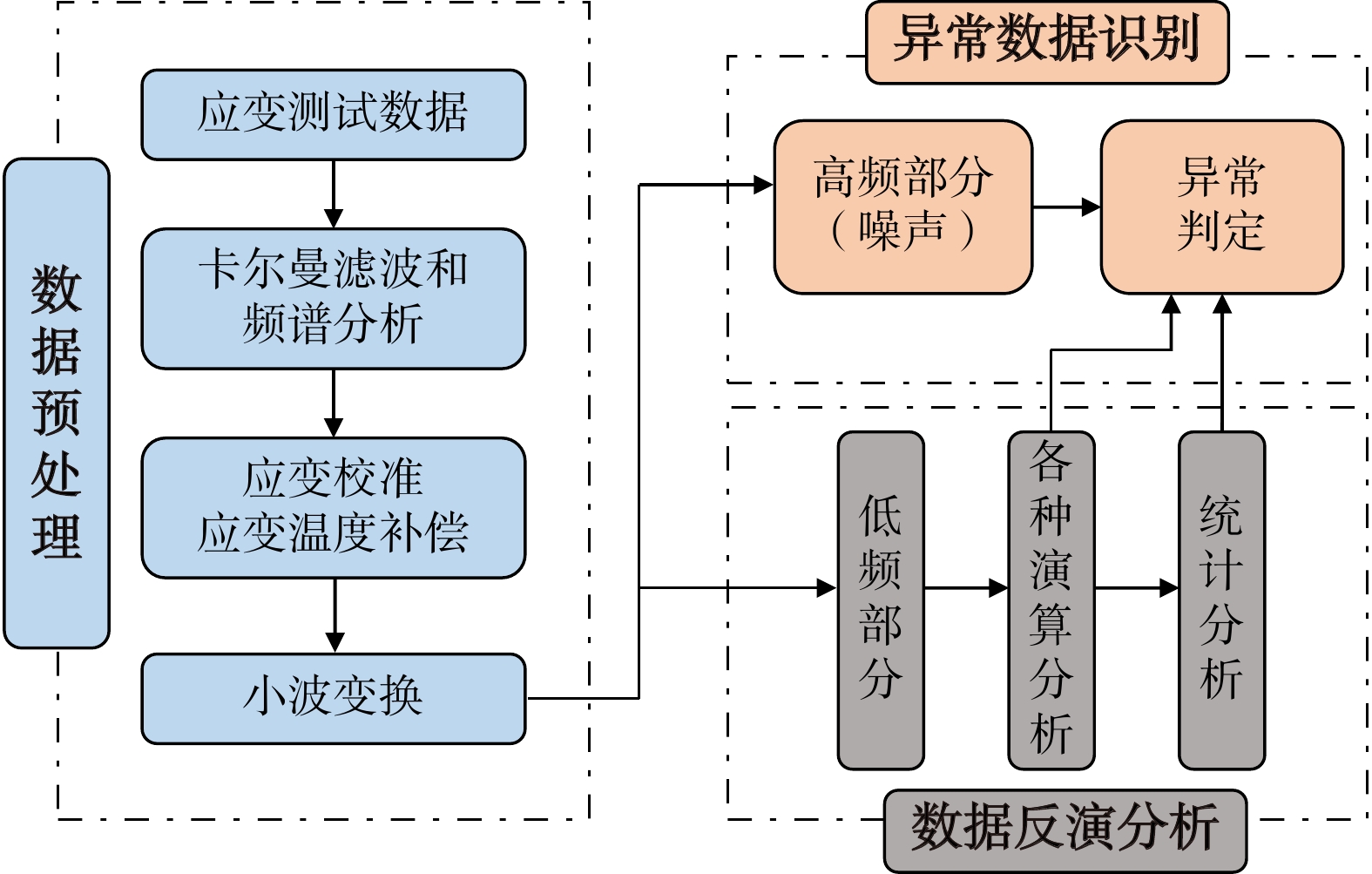
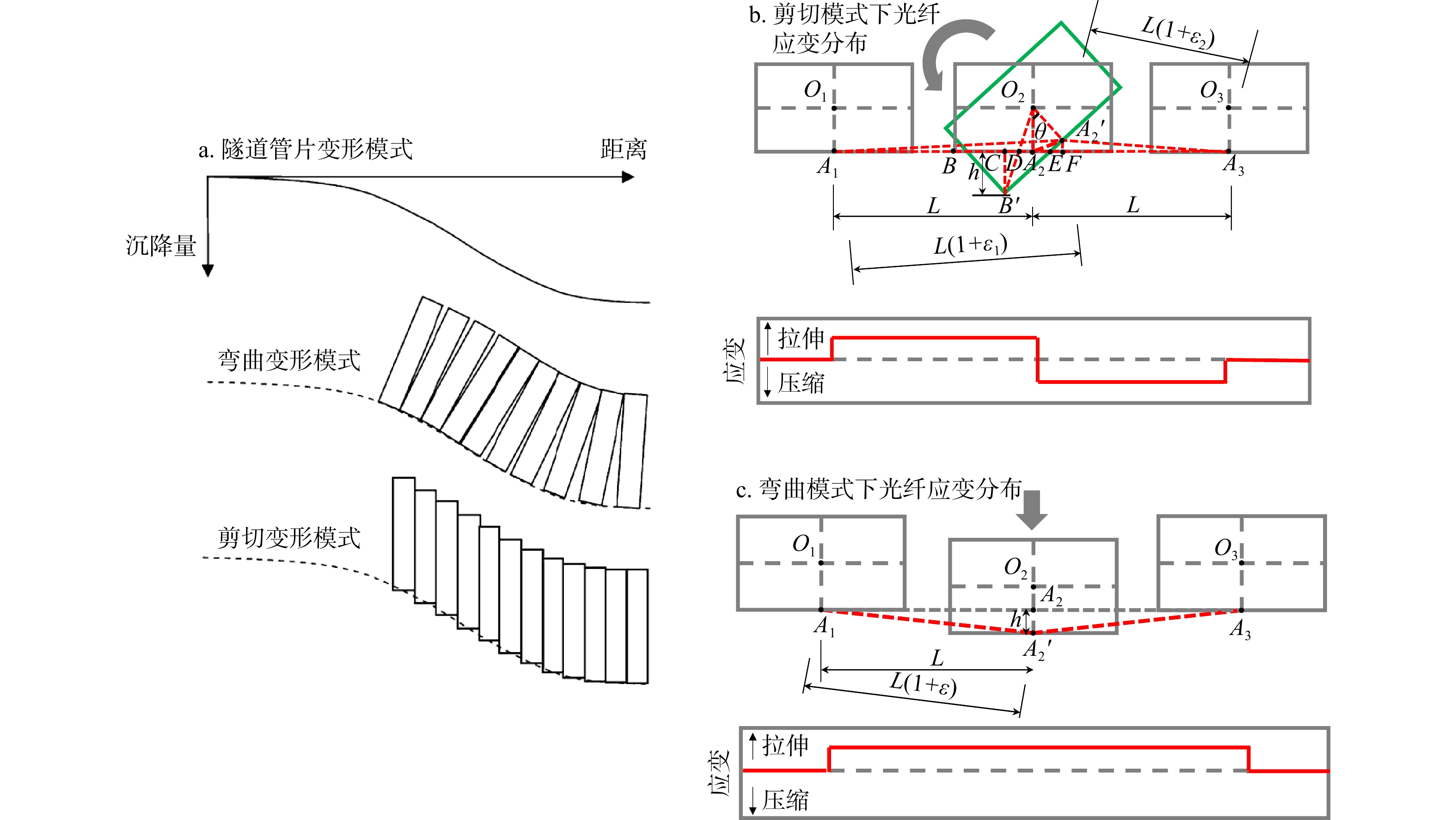
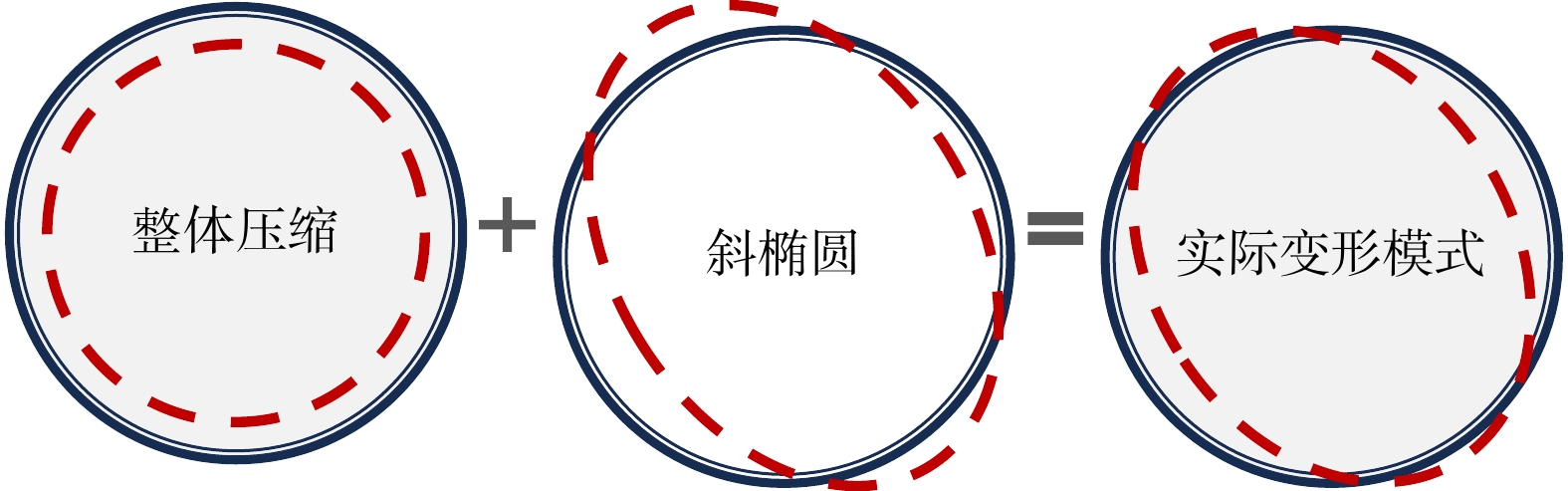
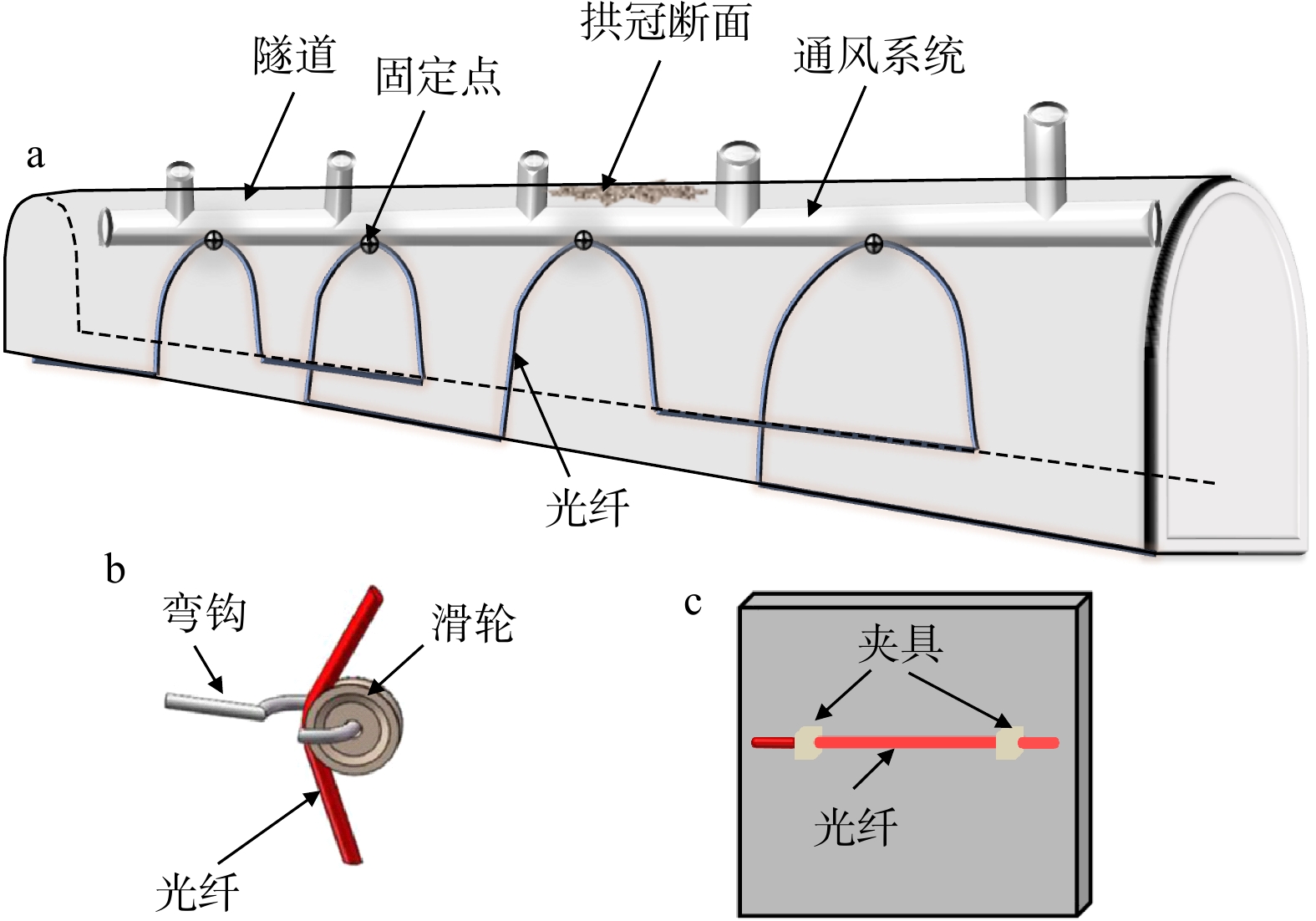
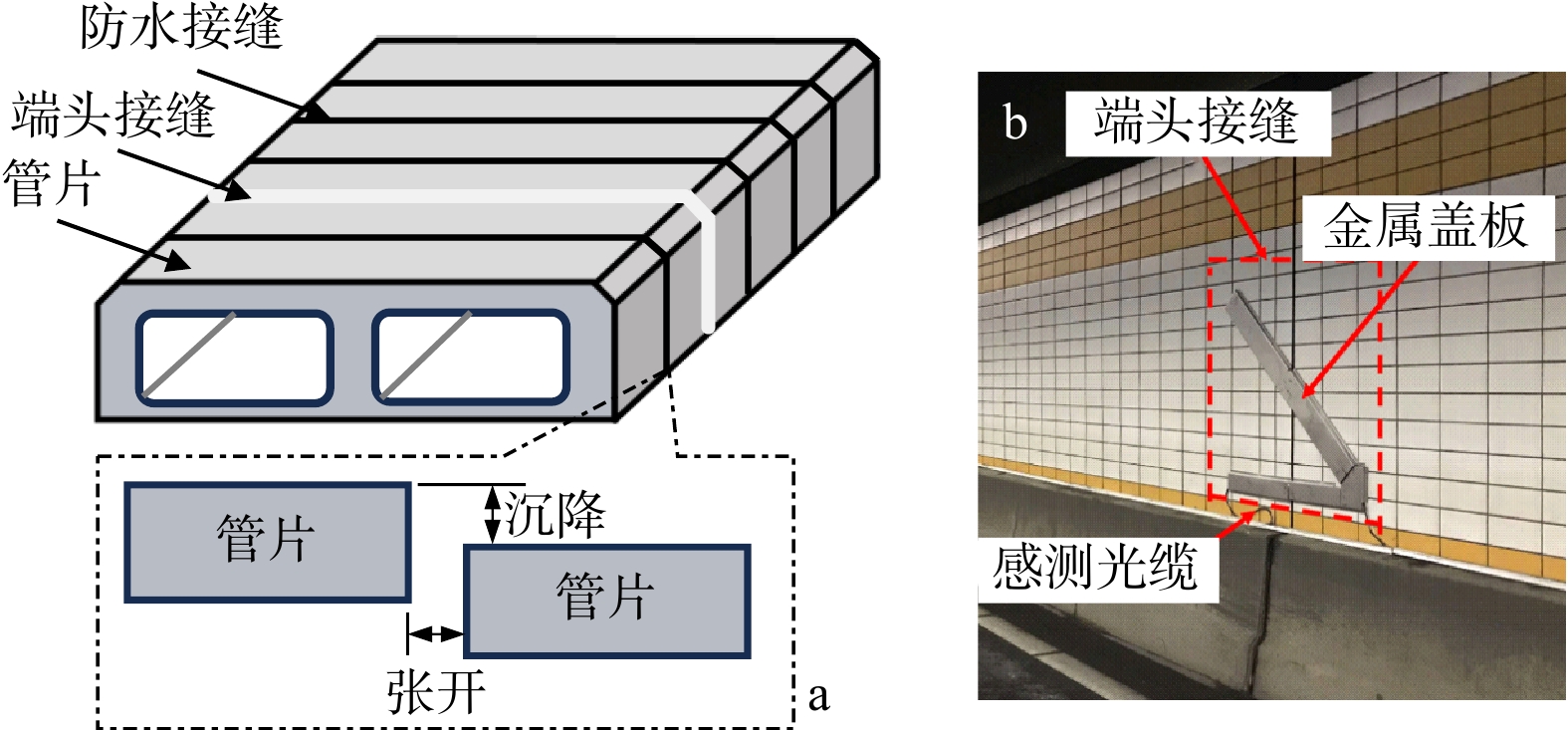
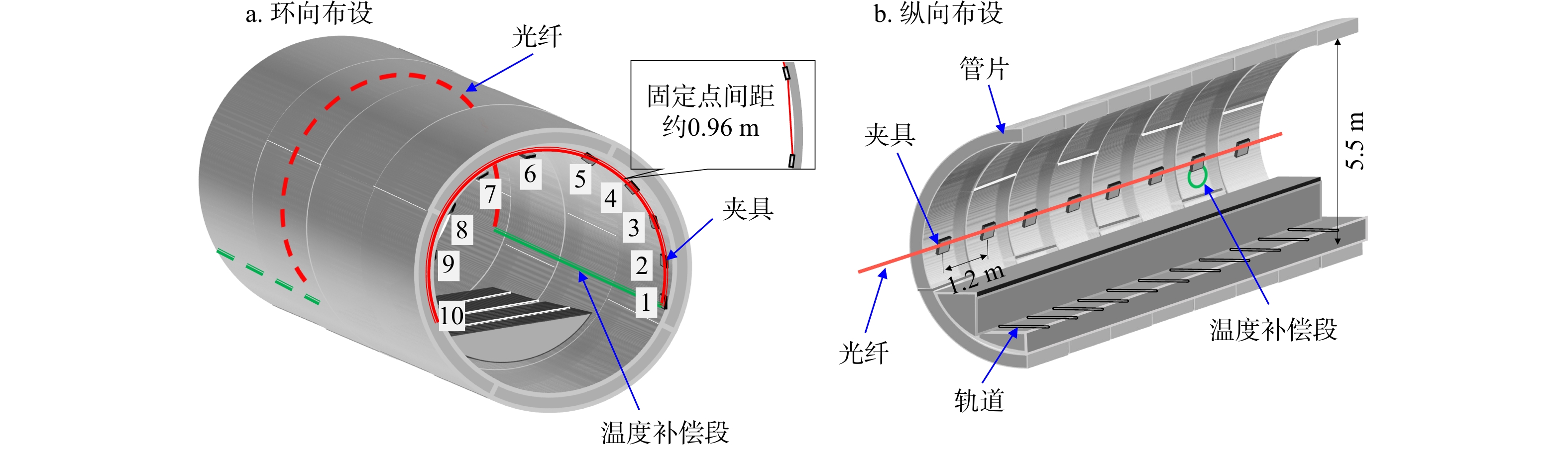
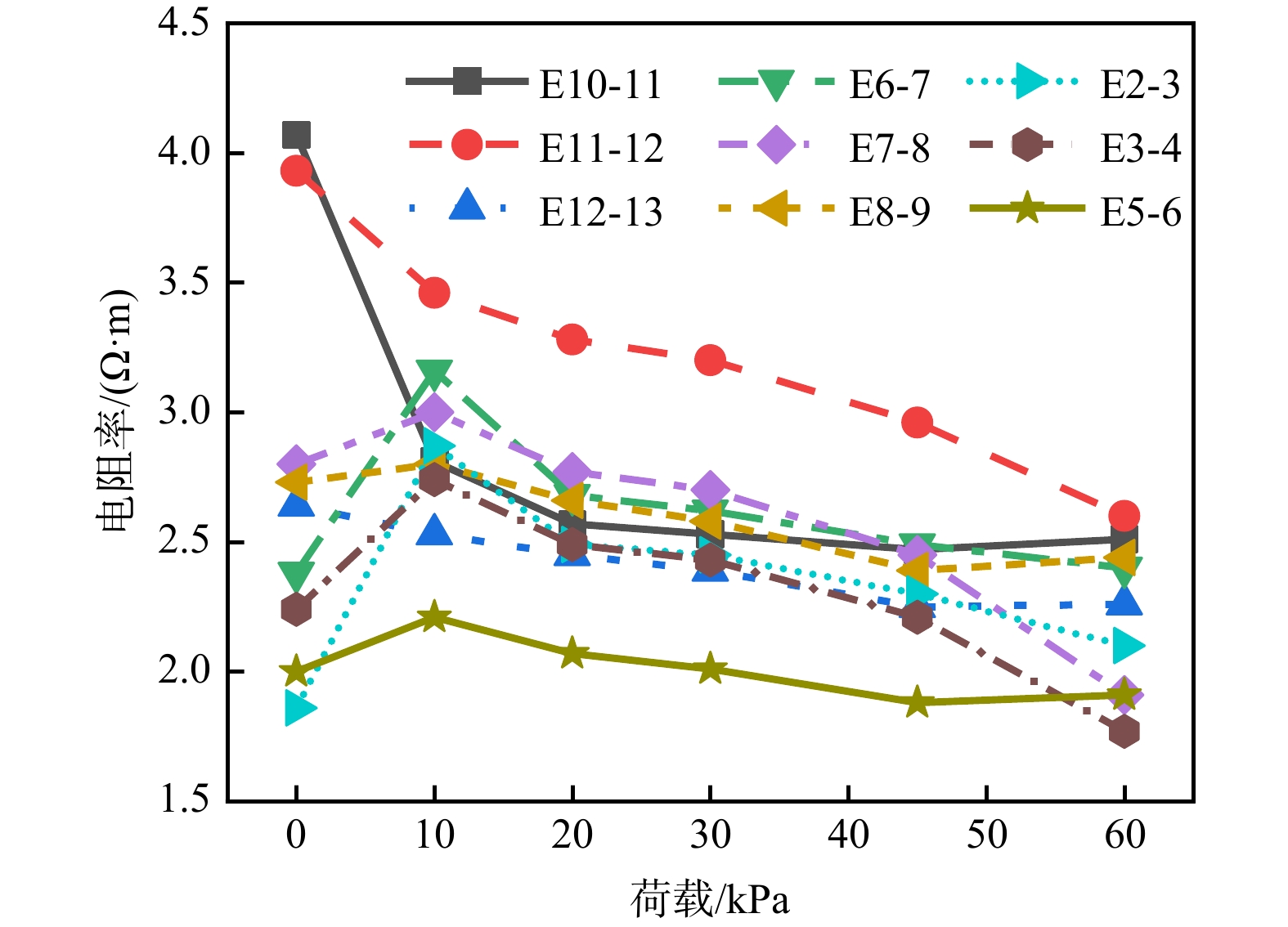
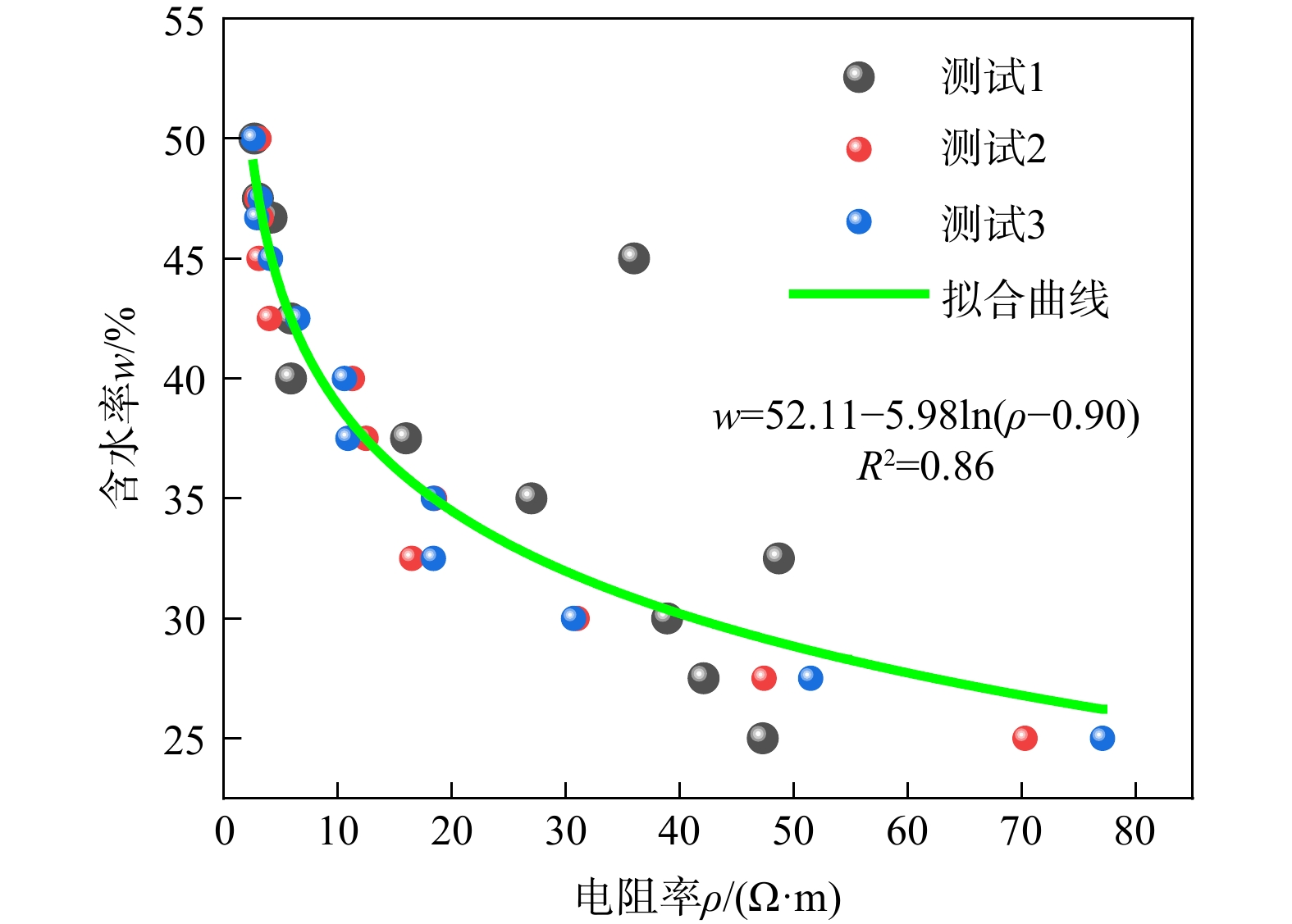
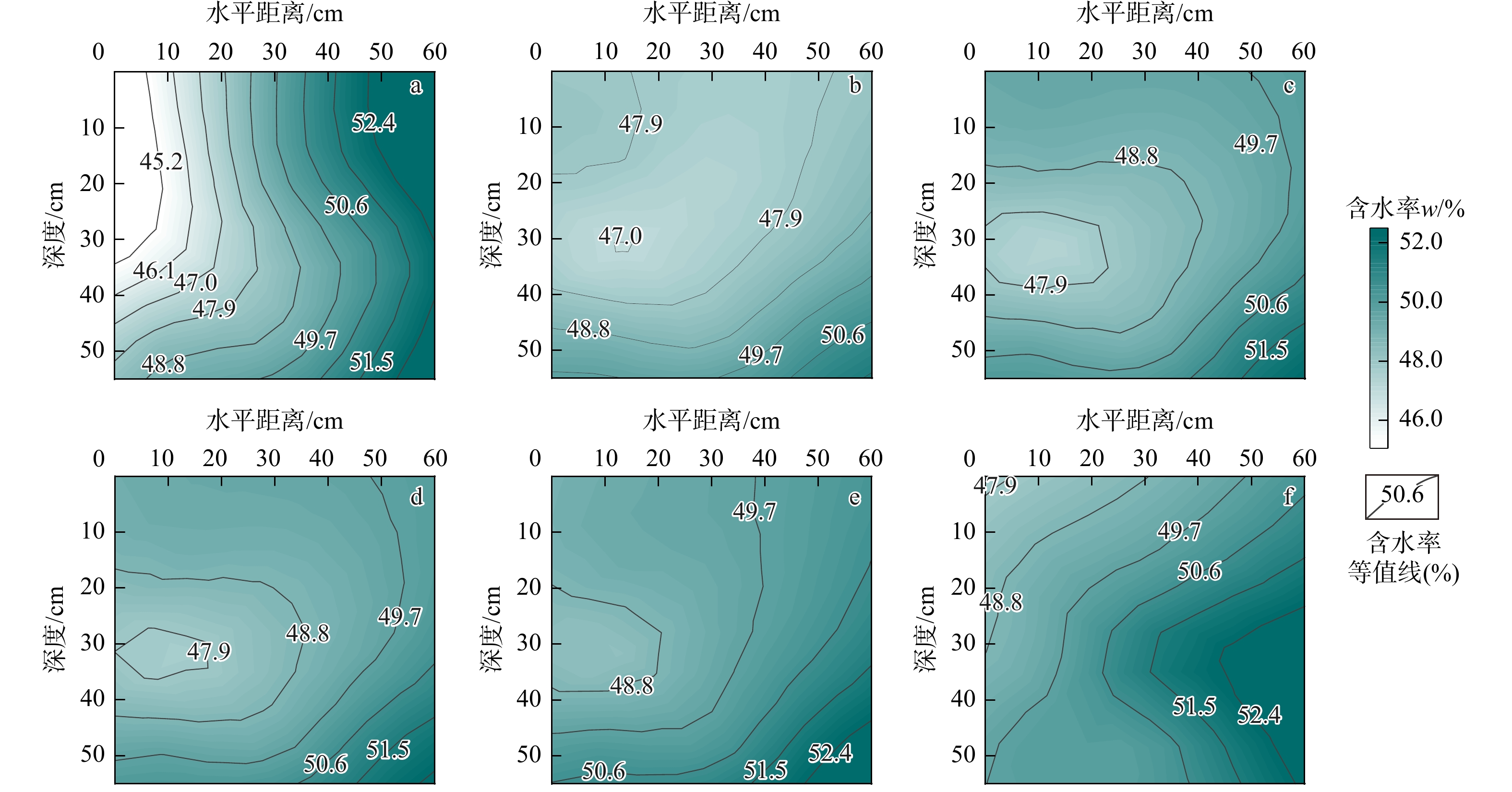
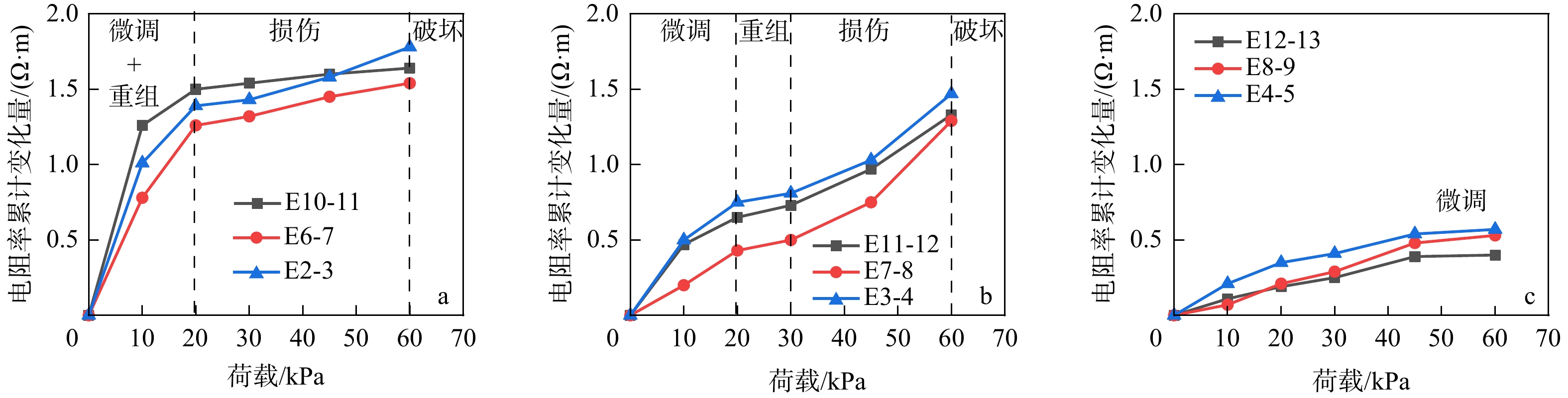
ProgressCombined with practical applications in tunnel engineering monitoring, this paper systematically introduces the fundamental principles, testing modes, and technical characteristics of Brillouin optical time-domain reflectometry (BOTDR) and Brillouin optical time-domain analysis (BOTDA), and reviews their research status and engineering applications in monitoring tunnel stress and deformation. Existing studies show that both BOTDR and BOTDA can provide distributed strain information along the sensing fiber, thereby overcoming the limitations of conventional point-based methods in spatial continuity and coverage. From the perspective of interaction among the sensing cable, tunnel structure, and surrounding rock, the applicability and error characteristics under different tunnel structural forms, fiber deployment methods, and coupling conditions are further analyzed. Particular attention is given to the influence of installation methods, such as surface bonding, groove embedding, internal embedding, and surface-attached laying, on strain transfer behavior and monitoring reliability. In addition, BOTDR and BOTDA are compared in terms of monitoring accuracy, spatial resolution, sensing distance, real-time performance, and adaptability to complex environments, so as to clarify their respective application scopes and technical advantages. The review indicates that monitoring performance depends not only on the sensing technology itself, but also on the coupling quality between the sensing cable and the structure, tunnel type, construction conditions, temperature variation, humidity, and other environmental disturbances.
Conclusions and ProspectsCombined with practical applications in tunnel engineering monitoring, this paper systematically introduces the fundamental principles, testing modes, and technical characteristics of Brillouin optical time-domain reflectometry (BOTDR) and Brillouin optical time-domain analysis (BOTDA), and reviews their research status and engineering applications in monitoring tunnel stress and deformation. Existing studies show that both BOTDR and BOTDA can provide distributed strain information along the sensing fiber, thereby overcoming the limitations of conventional point-based methods in spatial continuity and coverage. From the perspective of interaction among the sensing cable, tunnel structure, and surrounding rock, the applicability and error characteristics under different tunnel structural forms, fiber deployment methods, and coupling conditions are further analyzed. Particular attention is given to the influence of installation methods, such as surface bonding, groove embedding, internal embedding, and surface-attached laying, on strain transfer behavior and monitoring reliability. In addition, BOTDR and BOTDA are compared in terms of monitoring accuracy, spatial resolution, sensing distance, real-time performance, and adaptability to complex environments, so as to clarify their respective application scopes and technical advantages. The review indicates that monitoring performance depends not only on the sensing technology itself, but also on the coupling quality between the sensing cable and the structure, tunnel type, construction conditions, temperature variation, humidity, and other environmental disturbances.

 Submission System
Submission System